Il caso llms.txt: la storia di un file che “non serve a nulla” eppure Google lo usa, lo valuta e lo consiglia agli sviluppatori
📌 TAKE AWAYS
Google afferma che llms.txt non aiuta il posizionamento SEO, ma nel frattempo lo utilizza nei propri ambienti developer e lo include nei controlli di Chrome Lighthouse per gli agenti AI. Tra dichiarazioni di John Mueller, dati reali e nuovi strumenti agentici, emerge un quadro più complesso di quanto sembri.
Immagina che il tuo medico ti dica: “Non beva più acqua, fa malissimo alla salute!”
Incredulo lo saluti ed esci dal suo studio.
Appena chiusa la porta però ti rendi conto di aver dimenticato le chiavi e rientri nel suo studio, non fai in tempo a dire nulla che lo cogli in flagrante: il dottore sta bevendo avidamente una bottiglia d’acqua da due litri, così senza ritegno.
Ecco: questa è, più o meno, la sensazione che ha scosso la comunità SEO negli ultimi giorni, quando è saltato fuori che Google usa attivamente i file llms.txt e le pagine in formato markdown sui propri siti, dopo aver dichiarato pubblicamente e con una certa sicurezza che questi file “non servono” né per la ricerca, né per la SEO, e non migliorano le performance nel search.
La storia però è più intricata di quanto sembri.
E se hai un sito web, un e-commerce, o comunque lavori online per trovare clienti, vale la pena che tu la conosca bene.
Non perché devi correre subito a creare un file llms.txt (su questo torneremo), ma perché capire cosa sta succedendo nel mondo dell’indicizzazione IA ti mette in una posizione di vantaggio su molti tuoi concorrenti.
Cos’è un file llms.txt e perché se ne parla ovunque
Prima di entrare nel vivo della disputa, facciamo un passo indietro e partiamo dall’inizio.
Il file llms.txt è una proposta nata nel settembre 2024 da Jeremy Howard, co-fondatore di Answer.AI. L’idea è semplice quanto elegante: creare un file di testo in formato markdown, da posizionare nella directory principale del tuo sito (quindi a questo indirizzo: tuosito.com/llms.txt), che funzioni come una guida sintetica per le intelligenze artificiali che visitano le tue pagine.
Ma perché servirebbe una guida del genere?
Perché un sito web moderno è, dal punto di vista di un’IA, un posto caotico.
Ci sono menu, script JavaScript, banner pubblicitari, codice CSS, popup, widget e mille altri elementi che per un utente umano sono invisibili o irrilevanti, ma che un sistema di intelligenza artificiale deve comunque elaborare per arrivare al contenuto utile.
È come cercare di leggere un libro quando qualcuno ha incollato post-it su ogni pagina e riempito i margini di scarabocchi: il testo c’è, ma il rumore intorno è enorme.
Bene, un file llms.txt elimina questo rumore.
Presenta i contenuti essenziali del sito in un formato pulito, strutturato, leggibile da qualsiasi modello linguistico in pochi token. Può contenere una descrizione del progetto, i link alle pagine più importanti, la documentazione tecnica, le FAQ, le informazioni sui prodotti.
È pensato per sistemi come ChatGPT, Claude di Anthropic, Perplexity o Gemini, che sempre più spesso vengono usati dagli utenti non solo per fare domande generiche, ma per cercare informazioni su prodotti, aziende, servizi.
Poi esiste anche una versione “agentica” di questo file, che va ancora oltre.
Mentre un llms.txt standard si limita a descrivere cosa c’è nel sito, un llms.txt agentico spiega a un agente IA come interagire con quel sito: quali API usare, come effettuare un acquisto, come verificare la disponibilità di un prodotto, come compilare un modulo.
È la differenza che passa tra una mappa pensata per i turisti e una mappa topografica concepita per cartografi esperti.
Le risposte di John Mueller che hanno fatto discutere mezza internet
Arriviamo al cuore della storia. Lily Ray è la vicepresidente SEO Strategy and Research di Amsive, una delle voci più autorevoli e rispettate nel panorama SEO internazionale.
A dicembre 2025 solleva una questione che aveva già iniziato a circolare nelle conversazioni tra addetti ai lavori: molti siti stanno creando pagine separate in markdown o JSON da servire ai bot delle AI.
È una pratica lecita? Ha senso farlo?
Mueller risponde con scetticismo.
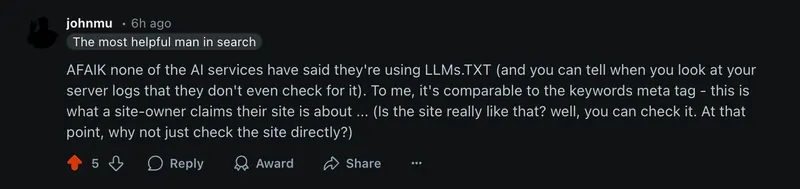
Le sue parole su Bluesky sono lapidarie:
“gli LLM hanno sempre lavorato bene con l’HTML standard, non vede motivi per cui dovrebbero aver bisogno di formati alternativi, e se davvero il markdown migliorasse la qualità delle risposte delle IA, sarebbero le stesse aziende come Google, OpenAI o Anthropic a dirlo pubblicamente”.
John Mueller
Poi, a fine 2025, il colpo di scena.
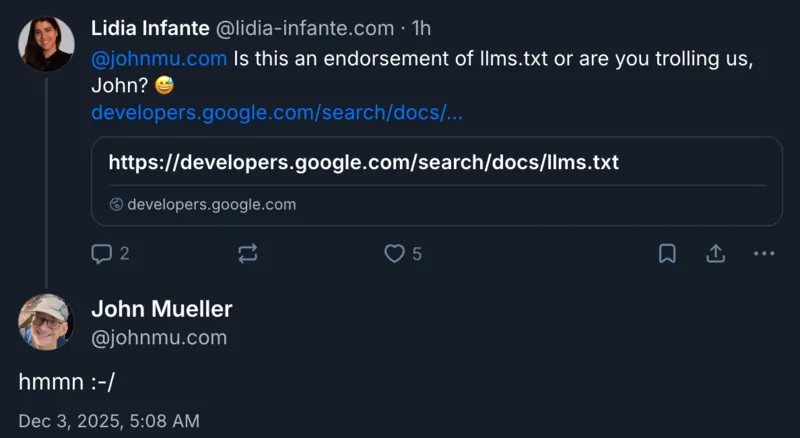
Succede qualcosa che fa alzare più di un sopracciglio: Lidia Infante, professionista SEO, scopre che Google ha silenziosamente caricato un file llms.txt sul suo portale di documentazione per sviluppatori, Search Central.
Lo fa notare su Bluesky con una domanda tagliente rivolta direttamente a Mueller:
“È un endorsement al llms.txt o ci stai trollando, John?”
La risposta di Mueller? Un imbarazzato e criptico “hmmn :-/” che, com’era prevedibile, non ha chiarito nulla. Il file viene poi rimosso lo stesso giorno.
La situazione si complica ulteriormente. Se Google usa file llms.txt e pagine markdown sui propri siti, come mai afferma pubblicamente che queste cose non servono alla ricerca? Non è un po’ contraddittorio?
La risposta di Mueller: tardiva, vaga e piena di “ma”
Ma Lily Ray non demorde. Il 20 maggio 2026 torna alla carica sul social BlueSky.
E Mueller finalmente, dopo mesi di dubbi e teorie, decide di chiarire la posizione di Google sugli llms.txt per mettere fine alle speculazioni (almeno nelle sue intenzioni).
La risposta breve che dà è questa:
“Non viene fatto per la Search. Esiste molto di più nei siti web oltre alla SEO.”
John Mueller
La versione lunga è più interessante. Mueller distingue tra due concetti che spesso vengono confusi: la “discovery”, cioè il fatto di essere trovati attraverso un motore di ricerca globale, e la “functionality”, che riguarda invece cosa succede dopo, quando qualcuno ha già trovato il tuo sito e deve portare a termine un compito.
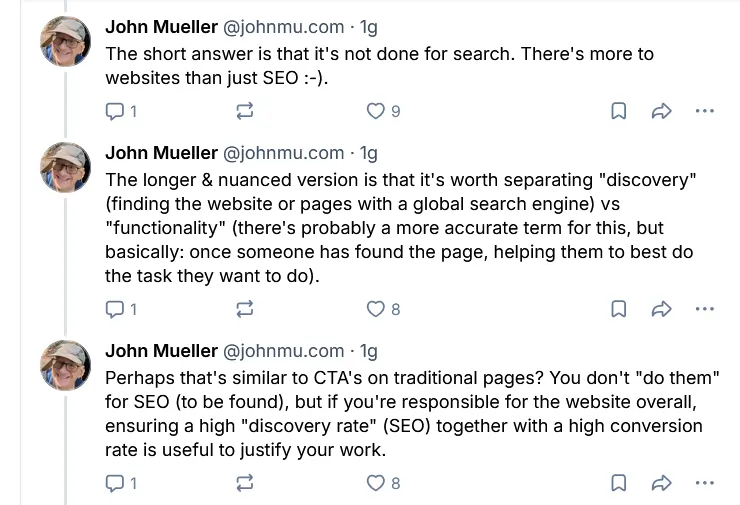
Per farla ancora più semplice, usa una metafora che chi lavora in ambito marketing capisce immediatamente: è come le call to action nelle pagine web.
Non le metti per posizionarti meglio su Google, ma se gestisci un sito nel suo insieme, assicurarti che gli utenti (umani o artificiali) trovino facilmente cosa fare è comunque parte del tuo lavoro.
Per quanto riguarda il sito developers.google.com nello specifico, Mueller è esplicito: la programmazione assistita dall’IA è diventata molto popolare, e i sistemi di coding AI funzionano meglio quando riescono a leggere e interpretare facilmente materiali di riferimento come la documentazione per sviluppatori.
Fornire il markdown di quella documentazione è, secondo lui, “probabilmente una soluzione temporanea, forse utile per risparmiare token.” Ovviamente le AI possono leggere l’HTML senza problemi: è più una questione di efficienza.
Poi arriva la parte che molti imprenditori con siti web come te dovrebbero leggere con attenzione.
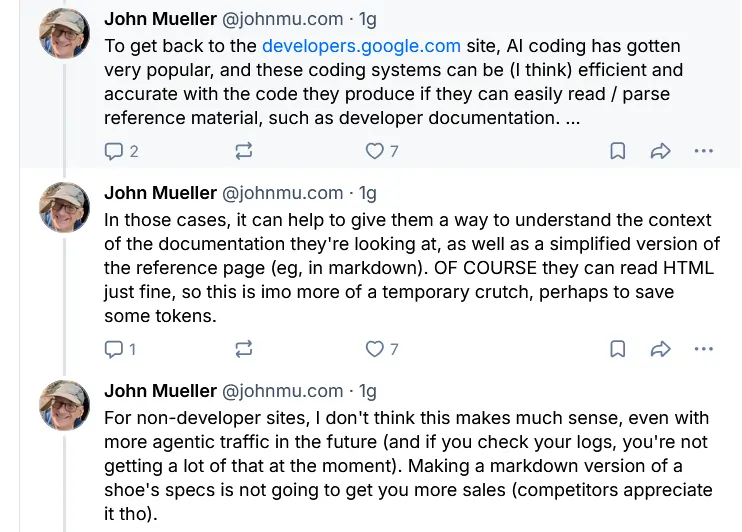
Mueller dice esplicitamente: per i siti non dedicati agli sviluppatori, non crede che queste cose abbiano molto senso, nemmeno pensando a un futuro con più traffico “agentico”.
Tradotto in termini pratici: creare una versione markdown delle specifiche di una scarpa non farà aumentare le vendite. E aggiunge, con una punta di ironia: “anche se ai concorrenti potrebbe far piacere,” perché un competitor potrebbe usare quei dati strutturati a suo vantaggio.
La chiusura è un invito a non inseguire scenari ipotetici:
“se pensate che sia importante prepararsi a quando gli agenti saranno ovunque: il vostro sito ha cose molto più importanti da fare per la SEO che prepararsi a una situazione futura potenziale che potrebbe arrivare oppure no. Date priorità alle necessità, non ai sogni.”
John Mueller

Però, nel frattempo, Google aggiunge llms.txt a Lighthouse
A questo punto arriva l’ironia più grande della storia.
Mentre il team di Google Search continua a ripetere che llms.txt non serve per la ricerca e che non riceve trattamento speciale, il team di Chrome fa esattamente il contrario.
Con l’uscita di Lighthouse 13.3, Google ha aggiunto una nuova categoria chiamata “Agentic Browsing” allo strumento di audit per sviluppatori più usato al mondo, quello integrato direttamente in Chrome DevTools e in PageSpeed Insights.
E in questa nuova categoria, uno dei controlli riguarda proprio la presenza del file llms.txt.
La documentazione ufficiale di Chrome for Developers è esplicita: senza llms.txt, “gli agenti potrebbero dover dedicare più tempo a scansionare il sito per comprenderne la struttura di alto livello e i contenuti primari.” Il file viene verificato automaticamente, e la sua assenza viene segnalata come un elemento che limita l’accessibilità del sito agli agenti AI.
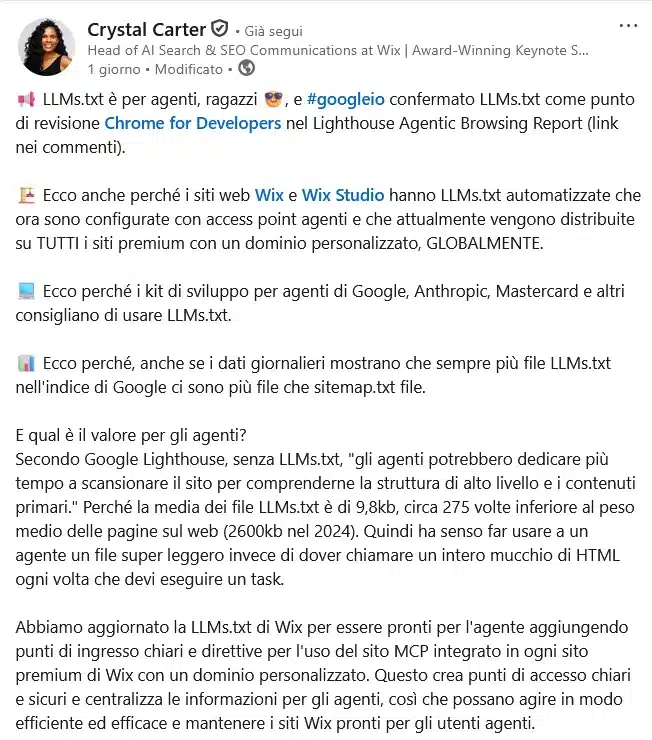
Crystal Carter, una delle figure di spicco della comunità SEO internazionale e voce autorevole su questi temi, ha commentato la novità con entusiasmo su LinkedIn, sottolineando che Big G durante il Google I/O 2026 ha confermato l’arrivo della validazione dei file llms.txt su Chrome come parte degli Agent Developer Tools.

In parole povere, llms.txt è per gli agenti, non per la ricerca tradizionale, e il fatto che Google stia costruendo strumenti per validarlo dice qualcosa di molto preciso sul futuro del web.
Carter fa anche notare un dato statistico che vale la pena sottolineare: nell’indice di Google ci sono già più file llms.txt che file sitemap.txt, e il peso medio di un file llms.txt è di 9,8 kilobyte, circa 275 volte inferiore al peso medio di una pagina web (2.600 kilobyte nel 2024).
Dal punto di vista di un agente IA che deve completare un compito, usare un file così leggero invece di caricare pagine HTML intere ogni volta ha un senso economico ed è sicuramente più efficiente.
Google Search VS Google Chrome: quando la mano destra non sa cosa fa la sinistra
A questo punto la situazione è cristallina nella sua complessità. Google Search dice: llms.txt non serve per il posizionamento. Google Chrome dice: controlla se i siti hanno llms.txt come parte della loro capacità di interagire con gli agenti AI.
Google Developers usa markdown e llms.txt nei propri siti. Google Search Central ha caricato e rimosso un llms.txt nello stesso giorno.
In pratica la guida di Google su llms.txt dipende da quale prodotto Google stai consultando…
Non proprio l’emblema della coerenza comunicativa!
Pedro Dias, specialista SEO con anni di esperienza alle spalle, ha provato a fare chiarezza distinguendo tra il file llms.txt come standard specifico e i file in formato markdown in generale.
La sua lettura è che i file markdown potrebbero essere utili per dare più contesto alle IA, indipendentemente da come vengono chiamati e da dove vengono posizionati.
L’esempio che porta è il file ai-optimization-guide.md.txt sul sito di Google Search stessa: tecnicamente non è un llms.txt, ma svolge una funzione simile. Il contenuto dunque conta più del contenitore.
Andrea Volpini: il formato conta, e i crawler lo confermano
Andrea Volpini, cofondatore di WordLift e tra i primi a studiare sistematicamente l’adozione di llms.txt, porta dati concreti a sostegno di una posizione più ottimistica. Il suo punto di partenza è chiaro: il markdown è ancora il formato preferito per il fine-tuning dei modelli linguistici, non l’HTML.
E i crawler di OpenAI, Microsoft e altri grandi attori dell’intelligenza artificiale stanno attivamente indicizzando i file llms.txt e llms-full.txt distribuiti sui siti dei suoi clienti.
Non sono ipotesi: sono dati di log.
La distinzione che fa Volpini è quella tra “orientamento” e “funzionalità”.
Il file llms.txt non è un protocollo di scoperta, nel senso che non ti farà comparire su Google per una parola chiave. Fornisce invece una panoramica di alto livello della documentazione, del contesto e delle informazioni che un agente può usare per capire cosa è disponibile su un sito e come procedere.
È un livello di comunicazione diverso, rivolto a sistemi che non cercano ma agiscono.
Volpini guarda anche oltre il presente immediato, segnalando approcci emergenti come agents.md, i file SKILL e la cartella .well-known/, che stanno evolvendo per includere WebMCP e il Universal Commerce Protocol.
Il punto è che gli agenti IA non devono solo leggere i siti: devono fare cose dentro i siti. E questo richiede un nuovo linguaggio, nuovi protocolli, nuove strutture.
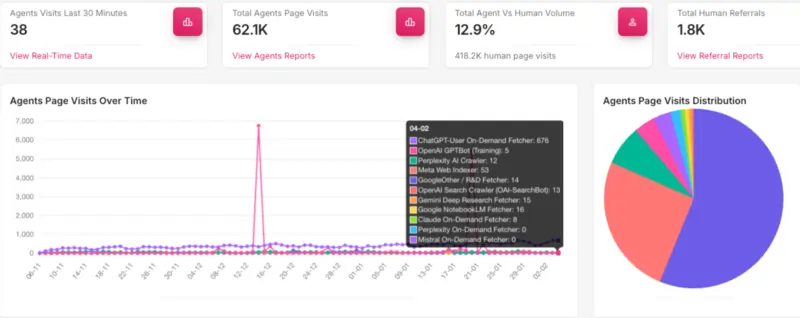
I dati di OtterlyAI: 62.000 visite IA, ma solo 84 al file llms.txt
A chiudere il cerchio ci pensa un esperimento che vorrei farti conoscere, perché porta numeri veri in una discussione spesso dominata da opinioni e aspettative.
OtterlyAI ha monitorato per novanta giorni consecutivi il traffico IA su un sito dotato di file llms.txt regolarmente implementato, tracciando ogni richiesta proveniente da bot di motori generativi, assistenti IA e strumenti basati su modelli linguistici.
Il risultato, fai molta attenzione, è stato eloquente nella sua semplicità: su 62.100 visite totali di bot IA registrate nel periodo, solo 84 hanno riguardato il file llms.txt.
Significa lo 0,1% del traffico IA complessivo.
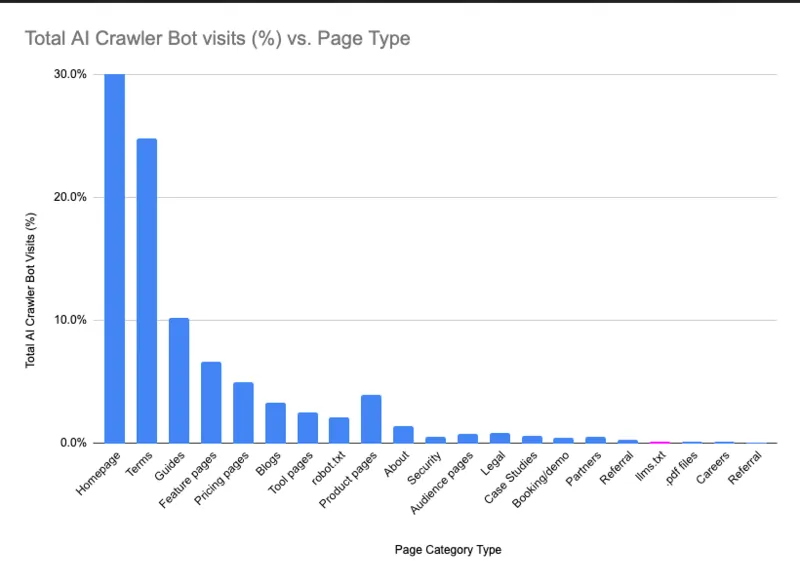
Per fare un confronto, una normale pagina di contenuto del sito riceveva in media circa 265 visite da bot IA nello stesso arco di tempo, vale a dire tre volte di più del file pensato appositamente per le intelligenze artificiali.
Cosa ci dice questo dato?
Fondamentalmente conferma quello che Mueller ha detto in modo meno tecnico: i grandi crawler AI, quelli di Google, Perplexity, OpenAI e compagnia, dispongono già di infrastrutture proprie per estrarre contenuto dall’HTML, “pulirlo” dal rumore e comprenderlo.
Non hanno bisogno di una scorciatoia. Il file llms.txt è invece potenzialmente utile per gli strumenti IA più piccoli, le applicazioni, i copilot integrati nei software, i bot di supporto clienti, tutti quei sistemi che non hanno alle spalle una pipeline di crawling industriale e per cui ricevere contenuto già pulito in formato markdown è un vantaggio reale in termini di costi e velocità di elaborazione.
Ma quindi John Mueller ha anche qualche ragione?
Aspetta un attimo. La morale dell’esperimento non è che llms.txt sia inutile in assoluto, ma che le aspettative su di esso vadano calibrate con precisione.
Chi lo implementa pensando di scalare nelle risposte di ChatGPT o di apparire più spesso nelle AI Overviews di Google rimarrà deluso.
Chi invece gestisce documentazione tecnica, API o contenuti pensati per essere integrati in prodotti IA di terze parti potrebbe trovarlo genuinamente vantaggioso.
Come sempre nel SEO, la domanda giusta da porsi non è “funziona?” ma “funziona per cosa, e per chi?”
Cosa significa tutto questo per te?
Dopo tutto questo giro, arriviamo alla domanda concreta che probabilmente ti stai facendo: devo creare un file llms.txt?
E se sì, quando, come, e perché?
La risposta onesta è: dipende da che tipo di sito hai e da quanto lavoro hai già fatto sulle basi.
Mueller ha ragione quando dice che se il tuo sito ha ancora problemi tecnici fondamentali, pagine lente, contenuti sottili, link building da costruire, allora occuparti di llms.txt sarebbe come mettere tende di design in una casa che non ha ancora le finestre. Le priorità contano.
Ma Mueller ha anche detto qualcosa di vero sull’altra sponda: il web sta diventando sempre più agentico. Gli assistenti IA che navigano per conto degli utenti, prenotano voli, confrontano prezzi, trovano fornitori, sono già qui.
ChatGPT ha introdotto la navigazione web, Claude di Anthropic può usare strumenti per interagire con i siti, Perplexity già oggi risponde a domande citando fonti specifiche e, come segnala Volpini, recupera attivamente i file llms.txt quando esistono.
Il fatto che Google stia aggiungendo un controllo su llms.txt in Lighthouse, lo stesso strumento che qualsiasi sviluppatore usa per verificare la qualità tecnica di un sito, non è un dettaglio trascurabile.
Certo, non è ancora un fattore di ranking, ma è un segnale di direzione. Google sta costruendo strumenti per misurare quanto i siti sono pronti per gli agenti. E anche Mastercard, Anthropic e Google stessi usano llms.txt nei loro kit di sviluppo per agenti.
Il vero punto che nessuno vuole dire ad alta voce
C’è una lettura di questa storia che va al di là del dibattito tecnico su un singolo file. Google sta vivendo una trasformazione interna: il suo prodotto storico, la ricerca tradizionale, è sotto pressione da parte di sistemi IA che rispondono direttamente alle domande senza rimandare a un sito web.
E allo stesso tempo, il suo motore di browser, Chrome, si sta preparando a diventare un agente che naviga per te.
Queste due anime di Google si trovano in momenti diversi del percorso. Il team di Search difende giustamente la distinzione tra ranking e accessibilità agli agenti: llms.txt non ti farà salire nelle SERP, questo è vero e va detto chiaramente.
Ma il team di Chrome sta già costruendo l’infrastruttura per un web in cui la domanda non è “riuscirò a essere trovato?” ma “riuscirò ad essere usato da un agente che agisce per conto dell’utente?“
Per chi ha un e-commerce, un sito di servizi, una piattaforma di prenotazioni, questa distinzione è enorme. Il traffico organico classico potrebbe contrarsi nei prossimi anni con l’espansione delle AI Overviews e delle risposte dirette.
Ma un nuovo tipo di traffico sta emergendo: quello degli agenti che cercano, confrontano, prenotano e acquistano. E per intercettarlo, le regole sono diverse da quelle della SEO tradizionale.
Da domani a fra cinque anni: dove guardare
La situazione è in fermento, e gli aggiornamenti si susseguono con una velocità che raramente si vede nel mondo SEO tradizionale.
Lighthouse 13.3 con la categoria Agentic Browsing è uscito nelle settimane scorse. Il check su llms.txt è già nei DevTools di Chrome. Google I/O ha confermato la direzione agentica di Chrome. I kit di sviluppo di Anthropic, Google e Mastercard già includono istruzioni su come strutturare i file per gli agenti.
Il consiglio pratico, senza allarmismi, è questo: tieni d’occhio questa evoluzione, ma non bloccare le attività SEO consolidate per rincorrerla. Se il tuo sito ha basi tecniche solide, contenuti di qualità e un lavoro di link building sensato, sei già in una buona posizione.
Se e quando arriverà il momento, ovvero (se) e quando llms.txt diventerà uno standard riconosciuto dai principali player AI, aggiungere quel file sarà un’operazione di poche ore.
Quello che invece vale fare oggi è capire come il tuo sito appare alle IA.
Perplexity ti cita quando qualcuno cerca i tuoi servizi? ChatGPT riesce a rispondere correttamente a domande sulla tua azienda? Claude, se interrogato sulla tua categoria di prodotti, ti include tra le opzioni?
Queste sono le domande della nuova frontiera della visibilità online. E rispondono a logiche parzialmente diverse da quelle di Google Search.
La storia di llms.txt, con tutte le contraddizioni di Google, è in fondo la storia di un settore intero che sta cercando di capire dove sta andando il web. E come sempre, le risposte definitive arriveranno dopo.
Ma chi osserva i segnali con attenzione, partirà sicuramente avvantaggiato.
Contatta la nostra agenzia SEO per sapere come il tuo business può approfittare di tutto ciò.
Google utilizza llms.txt ma dice che non serve: domande frequenti
Che cos’è un file llms.txt?
Un file llms.txt è un file di testo in formato markdown, posizionato nella directory principale di un sito, pensato per offrire alle intelligenze artificiali una guida sintetica ai contenuti più importanti. Può includere descrizioni, link rilevanti, documentazione tecnica, FAQ e informazioni utili per aiutare i modelli linguistici a comprendere meglio il sito.
llms.txt serve per migliorare il posizionamento su Google?
No, secondo John Mueller di Google, llms.txt non viene usato per migliorare il posizionamento nella Search e non è un fattore SEO. Il suo possibile valore riguarda soprattutto l’accessibilità del sito per agenti AI, strumenti di coding, copilot e sistemi che devono leggere o usare contenuti in modo più efficiente.
Quando può essere utile creare un file llms.txt?
Un file llms.txt può essere utile soprattutto per siti con documentazione tecnica, API, piattaforme SaaS, e-commerce complessi o contenuti pensati per essere usati da strumenti di intelligenza artificiale. Per siti con problemi SEO di base, pagine lente o contenuti deboli, resta una priorità secondaria rispetto alle attività fondamentali di ottimizzazione.
