Ho provato a fare la classifica dei migliori modelli di intelligenza artificiale. Poi ho smesso, e ti spiego perché
📌 TAKE AWAYS
I benchmark dell’intelligenza artificiale sono spesso usati per classificare i migliori modelli, ma non sempre riflettono le prestazioni nel mondo reale. Tra contaminazione dei dati, test di laboratorio e strategie di marketing, molti risultati rischiano di essere fuorvianti. Ecco perché la scelta di un modello dovrebbe basarsi soprattutto su prove concrete nel proprio contesto operativo.
Stavo per farlo. Davvero. Avevo già quasi tutto pronto: tabelle, percentuali, nomi di modelli in grassetto, una bella classifica con medaglie e tutto il resto.
Gemini 3.1 Pro per la ricerca scientifica, Claude Opus per il codice, GPT-5 per uso generico.
Chiaro, pulito, condivisibile. Il tipo di articolo che si mette nei preferiti e si cita nelle riunioni.
Poi mi sono fermato.
Non perché i dati fossero sbagliati. Ma perché ho cominciato a chiedermi cosa misurano davvero quei dati. E da lì, come spesso accade, non si torna più indietro.
Se lavori online, hai un e-commerce, un sito, una newsletter, un’agenzia o qualsiasi attività che dipende dalla visibilità sul web, probabilmente ti sei già fatto questa domanda almeno una volta:
Quale intelligenza artificiale dovrei usare?
È una domanda legittima. Anzi, è la domanda giusta.
Il problema è che le risposte che trovi in giro si basano quasi tutte su qualcosa di molto meno solido di quanto sembri.
Partiamo dai fatti concreti, perché di dati in questo campo ne circolano tanti, e vale la pena capire da dove vengono.
La classifica che quasi ho pubblicato
I Large Language Models, gli LLM, sono i sistemi di intelligenza artificiale alla base di ChatGPT, Gemini, Claude, DeepSeek, Grok e compagni. Ognuno ha caratteristiche diverse, legate al modo in cui è stato addestrato e agli obiettivi per cui è stato progettato.
Per confrontarli, l’industria usa i cosiddetti benchmark: test standardizzati progettati per misurare abilità specifiche come ragionamento, programmazione o conoscenza scientifica, come riporta bene Wired.
Nel mio articolo originale avevo usato dati precisi, e te li condivido comunque, perché sono utili per avere un’idea generale sulle performance dei modelli più noti.

Ma cosa valutano di preciso i vari benchmark? E quale LLM ne esce meglio?
Per la ricerca accademica, il benchmark GPQA Diamond (Graduate-Level Google-Proof Q&A) valuta domande di fisica, chimica e biologia a livello universitario avanzato.
Domande costruite appositamente per essere impossibili da risolvere con una semplice ricerca online. Qui Gemini 3.1 Pro di Google DeepMind raggiunge il 94% di accuratezza, seguito da GPT-5.4 di OpenAI con il 93% e Claude Opus 4.6 di Anthropic con il 91%.
Margini sottili, prestazioni altissime.
Nel campo della programmazione, il benchmark SWE-bench Verified simula 2.294 problemi reali tratti da repository GitHub, su 12 dei progetti Python più diffusi. I modelli devono analizzare interi progetti software, capire la descrizione di un errore e proporre una modifica al codice che funzioni davvero.
Il leader qui è Claude Opus 4.5 in modalità ragionamento elevato, con un punteggio del 76,8%, seguito a pari merito da Gemini 3 Flash e MiniMax M2.5 con il 75,8%.
Per il ragionamento complesso, il riferimento è Chatbot Arena, gestito da LMSYS: oltre 5 milioni di valutazioni “alla cieca”, dove utenti reali chattano con due modelli senza sapere quale sia quale e scelgono la risposta migliore. Il punteggio usato è il sistema Elo, lo stesso degli scacchi.
Al momento, in testa c’è Gemini 3.1-Pro con 1505 punti, seguito da Claude Opus 4.6 Thinking con 1503 e Grok-4.20 con 1496.
Tutto molto chiaro, vero? Dati, nomi, numeri. Il tipo di materiale che sembra oggettivo per definizione.
Poi è arrivata la ricerca di Oxford
Quando stavo per pubblicare questo approfondimento sulle performance degli LLM, mi sono ricordato di una ricerca dell’Oxford Internet Institute che ha messo in discussione tutto questo impianto.
Se ti ricordi, te ne avevo parlato qui.
Il dato più citato: l’84% dei benchmark IA è inaffidabile. Non approssimativo. Non parziale. Inaffidabile.
Language Model Benchmarks“
Il problema principale si chiama contaminazione dei dati.
Molti benchmark sono pubblici da anni. I dataset usati per addestrare i modelli sono enormi, spesso costruiti raccogliendo testo da tutto il web. La probabilità che le risposte corrette di un benchmark pubblico siano finite nel materiale di addestramento di un modello è concreta. In pratica, il modello non ragiona: ricorda. Come uno studente che ha studiato le risposte dell’esame prima di entrare in aula.
A questo si aggiunge un secondo problema, strutturale. I benchmark misurano performance su compiti isolati, con risposte giuste o sbagliate. Ma un’analisi di oltre quattro milioni di prompt reali ha mostrato che le persone usano l’IA per tutt’altro: assistenza tecnica, revisione di documenti, generazione di testi, riassunti, attività collaborative. Roba pratica, contestuale, difficile da incasellare in una risposta unica e verificabile.
E poi c’è il problema del marketing. Come ha documentato la ricerca dell’OII, le aziende possono ottimizzare i modelli specificamente per un benchmark, tentare la valutazione un numero illimitato di volte e riportare selettivamente solo i risultati migliori. Spesso senza violare alcuna norma, semplicemente perché le norme non esistono.
È un “Wild Wild West”, per citare il titolo di un film strano e trascurabile con Will Smith. Parliamo di un settore in cui distinguere i progressi autentici dal clamore pubblicitario è diventato quasi impossibile.
Ogni comunicato stampa di ogni grande azienda tech arriva con toni trionfalistici. Il nuovo modello “rivoluziona”, “supera tutti i competitor”, “ridefinisce i limiti”, è “un passo in avanti verso l’AGI!”, addirittura.
I benchmark vengono mostrati come prove oggettive.
Ma oggettivi per chi? Costruiti come? Con quale metodologia? Con quali domande selezionate da chi?
Il MIT ha alzato la voce
Proprio di questi temi tratta l’articolo del 31 marzo 2026 firmato da Angela Aristidou, professoressa all’University College London e faculty fellow allo Stanford Digital Economy Lab.
Il suo argomento è semplice e devastante: l’IA non viene mai usata nel modo in cui viene testata.
I benchmark valutano l’IA in laboratorio, su compiti singoli, in condizioni controllate. Ma nella realtà, l’IA opera all’interno di team, processi organizzativi, flussi di lavoro distribuiti nel tempo. La performance reale emerge solo in questi contesti, dopo periodi prolungati di utilizzo.
L’esempio che Aristidou porta è quello della sanità. Sistemi IA che leggono scansioni mediche con precisione altissima, approvati dalla FDA, con benchmark stellari. Eppure, nei reparti di radiologia di ospedali in California e nel Regno Unito, Aristidou ha osservato direttamente che quegli stessi sistemi rallentavano il lavoro clinico.
I professionisti dovevano interpretare gli output dell’IA insieme agli standard di reportistica specifici dell’ospedale, alle normative nazionali, ai protocolli multidisciplinari. Quello che sembrava uno strumento di produttività diventava un ostacolo.
Il motivo è che le decisioni cliniche non vengono prese da un singolo medico davanti a un singolo test. Radiologi, oncologi, fisici e infermieri lavorano insieme, su pazienti il cui quadro clinico evolve nel tempo.
Un modello che ottiene il 98% di accuratezza su una singola scansione in laboratorio può essere completamente inadatto a questo contesto. E i benchmark attuali non lo rileverebbero mai.
Aristidou ha chiamato questo fenomeno “AI graveyard”: il cimitero in cui finiscono i modelli con benchmark brillanti che, una volta integrati nei processi reali, vengono abbandonati dopo aver consumato tempo, denaro e fiducia organizzativa.
Cosa significa tutto questo per chi lavora online?
Se hai un sito, un e-commerce o una qualsiasi attività digitale, e stai valutando quali strumenti IA adottare per aumentare il traffico, migliorare i contenuti o automatizzare parte del lavoro, questo ragionamento ti riguarda direttamente.
Le classifiche che leggi online, inclusa quella che stavo per pubblicare io, ti dicono quale modello è più bravo a risolvere problemi di fisica universitaria o a correggere codice Python su GitHub.
Non ti dicono quale funziona meglio integrato nel tuo flusso di lavoro reale, con i tuoi collaboratori, per i tuoi obiettivi specifici, nel corso delle settimane!
Come ha osservato anche Andrea Signorelli durante la nostra intervista, questa situazione trasforma la valutazione in un esercizio di memoria collettiva, non di intelligenza applicata. E al massimo dovremmo parlare di performance, non di intelligenza!
E le aziende che si fidano ciecamente dei benchmark per prendere decisioni di investimento rischiano di ritrovarsi con strumenti ottimizzati per superare test che non hanno nulla a che fare con i problemi reali che devono risolvere.
Il report AI Index 2025 della Stanford University fotografa bene il paradosso: ci sono modelli capaci di risolvere problemi da olimpiadi di matematica che però faticano su compiti di ragionamento più complessi nel mondo reale.
Insomma, senza un metro di giudizio affidabile, si continua a costruire aspettative su fondamenta fragili.
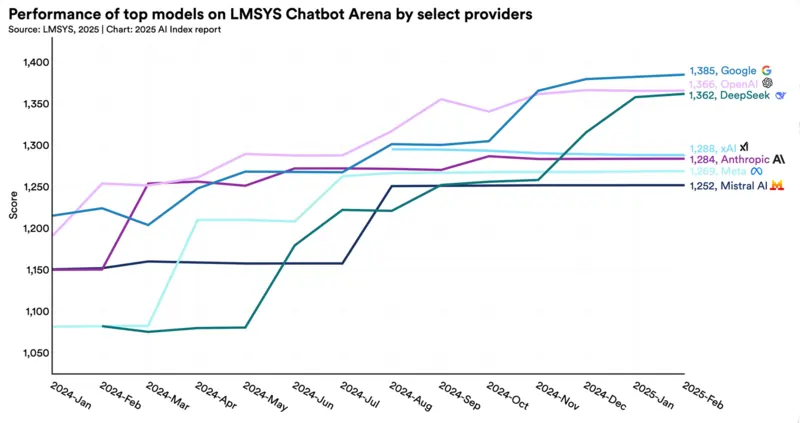
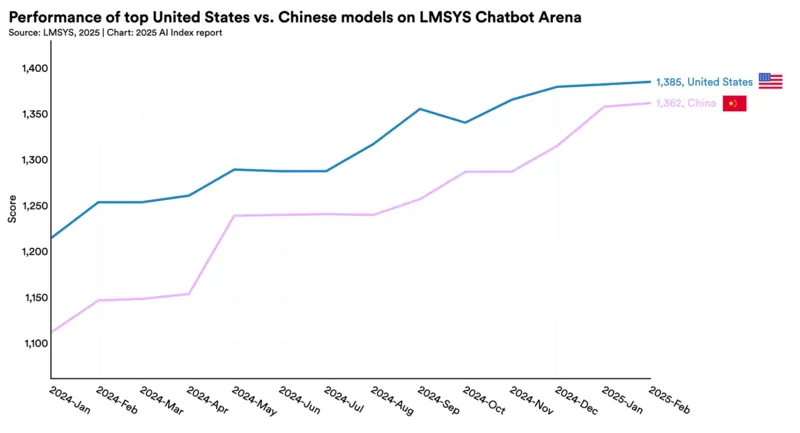
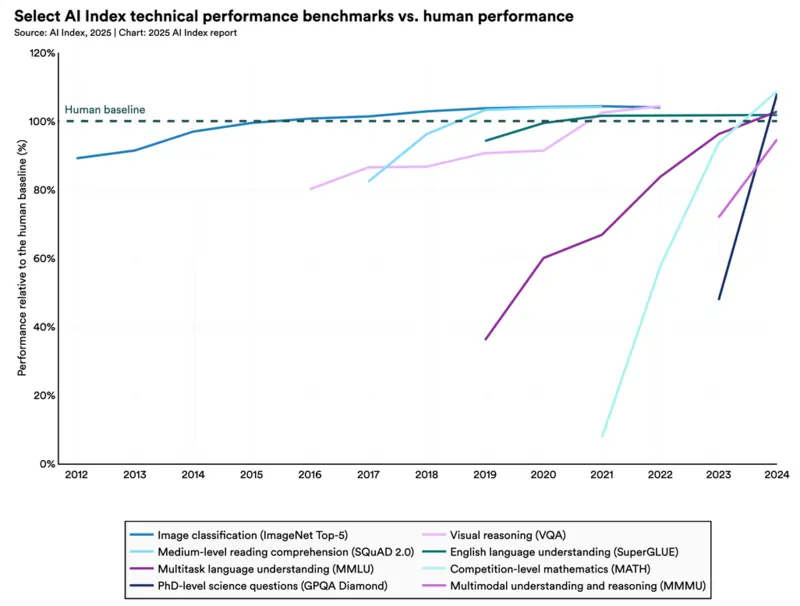
Qualcosa si sta muovendo
C’è una buona notizia, però. La consapevolezza di questi limiti sta crescendo, e con essa le prime risposte concrete.
Greg Kamradt della Arc Prize Foundation ha lanciato “ARC Prize Verified“, un programma pensato per introdurre maggiore rigore nella valutazione dei sistemi di frontiera. Gli stessi autori della ricerca dell’OII che ti ho citato più su hanno proposto otto raccomandazioni per migliorare la qualità dei benchmark, ispirandosi alle pratiche consolidate nella valutazione umana.
La professoressa Aristidou, dal canto suo, parla di benchmark HAIC, Human-AI Context-Specific Evaluation: valutazioni che misurano non solo accuratezza e velocità, ma anche il coordinamento nei team, la rilevabilità degli errori nel tempo, gli effetti a monte e a valle del processo decisionale.
L’idea non è testare cosa sa fare un modello da solo, ma come migliora o compromette il lavoro collettivo degli esseri umani in un contesto specifico. Qualcosa di molto più difficile da standardizzare, ma anche molto più vicino alla realtà.
Quello che i numeri non ti dicono
Torno quindi al punto di partenza. Ho quasi pubblicato una classifica. I dati erano reali, i benchmark citati esistono, i punteggi sono quelli che circolano nelle riviste di settore. Ma presentarli come verità assoluta sarebbe stato un disservizio.
Non ti dirò mai che un LLM è migliore di un altro sempre, in qualsiasi contesto, per qualsiasi compito. E non farò mai da cassa di risonanza ai comunicati trionfanti (e pubblicitari) delle Big Tech di turno…
Al massimo ti parlerò della mia esperienza personale con un dato modello, per una determinata attività, per un obiettivo preciso.
Proprio per questo, la prossima volta che leggi che un modello IA “supera tutti i competitor” su un benchmark specifico, fatti qualche domanda. Chi ha costruito quel test? Il modello è stato addestrato su dati che potrebbero aver incluso le risposte? Quella performance in laboratorio si traduce in qualcosa di utile per il tuo lavoro reale, nel tuo contesto, con i tuoi processi?
I benchmark sono uno strumento utile. Ma limitato.
Il salto di qualità vero, per chi usa l’IA nel proprio business, sta nel testare i modelli nel proprio contesto specifico, osservarne i risultati nel tempo, e non affidare le decisioni a classifiche costruite in laboratorio da aziende che hanno tutto l’interesse a vincerle.
I benchmark non sono così oggettivi come pensi: domande frequenti
I benchmark dell’intelligenza artificiale sono davvero affidabili?
Non sempre. Secondo la ricerca citata dell’Oxford Internet Institute, l’84% dei benchmark IA risulta inaffidabile. I principali problemi riguardano la contaminazione dei dati di addestramento, la misurazione di compiti troppo isolati e la possibilità per le aziende di ottimizzare i modelli specificamente per superare determinati test.
Perché i benchmark non riflettono sempre l’uso reale dell’IA?
I benchmark testano i modelli in condizioni di laboratorio, su task singoli e controllati. Nella realtà, invece, l’intelligenza artificiale viene utilizzata all’interno di team, processi aziendali e flussi di lavoro complessi. Per questo motivo un modello eccellente nei test può rivelarsi poco efficace nel contesto operativo reale.
Come scegliere il modello IA migliore per il proprio business?
Il criterio più efficace non è affidarsi solo alle classifiche pubblicate dai benchmark, ma testare i modelli nel proprio contesto specifico. È importante valutare come si integrano nei processi di lavoro, nei team e negli obiettivi aziendali nel medio periodo, osservando risultati concreti nel tempo.

Queste classifiche sono il motore di una fuoriserie testato al banco: numeri impressionanti, ma inutili. Se poi monti quel motore su un’auto e non riesce a fare una salita, a cosa ti è servito? L’unica prova che conta è quella sulla strada del mercato.
Le classifiche sono un teatrino di marionette. Le aziende tirano i fili dei dati per gonfiare i risultati. Nella pratica, il sipario cala. Lavoro con i dati, non con le illusioni.