Con il nuovo dataset pubblico di Schema.org, ora sappiamo quali dati strutturati usano i siti che i motori di risposta IA considerano fonti affidabili. Il tuo è tra di loro?
📌 TAKE AWAYS
Google e Schema.org hanno pubblicato il primo dataset pubblico che mostra come vengono utilizzati i dati strutturati sul web.
Una novità che aiuta a comprendere come migliorare la visibilità nei motori di ricerca e nei sistemi di intelligenza artificiale.
Ci sono mattine in cui apri le statistiche del tuo sito e ti sembra che tutto vada bene. Il posizionamento regge, le visite ci sono, qualche richiesta di contatto arriva.
Nessun click.
Le persone cercano, leggono la risposta direttamente in pagina, e vanno avanti con la loro giornata. Senza passare da te. Senza passare da nessuno.
Se gestisci un’attività online, che si tratti di un e-commerce, di uno studio professionale, di un’agenzia o di qualsiasi altra cosa che dipende dalla visibilità sul web per portare clienti, questa statistica non è un dettaglio tecnico secondario.
Numeri come questi non cambiano il titolo di un convegno: cambiano i conti a fine mese di chi vive di visibilità.
E proprio in questo contesto, all’inizio di giugno 2026, è arrivata una notizia che nella comunità degli esperti di SEO e dati strutturati ha fatto abbastanza rumore, anche se probabilmente non è arrivata sui tuoi radar.
Schema.org, in collaborazione con Google, ha pubblicato un dataset pubblico che per la prima volta mostra in modo aggregato quanto vengono effettivamente usati i dati strutturati sul web.
Seguimi, perché è una questione che ti riguarda direttamente, e vale la pena capire perché.
Cos’è Schema.org e perché devi assolutamente conoscerlo
Prima di entrare nella novità, facciamo un passo indietro perché non ha senso dare nulla per scontato. Schema.org è un vocabolario condiviso nato nel 2011 da una collaborazione tra Google, Bing, Yahoo e Yandex, i principali motori di ricerca dell’epoca, con un obiettivo molto preciso: creare un linguaggio comune che permettesse ai siti web di comunicare alle macchine il significato di quello che contengono, non solo le parole, ma il senso.
Quando scrivi sul tuo sito che Marco Rossi è l’autore di un articolo pubblicato il 15 marzo 2026, un motore di ricerca vede del testo.
Quando aggiungi un markup strutturato secondo lo standard Schema.org, il motore di ricerca capisce che “Marco Rossi” è una persona con un ruolo specifico, che “15 marzo 2026” è una data di pubblicazione, che quell’articolo appartiene a una categoria precisa.
La differenza tra leggere parole e comprendere relazioni tra entità è esattamente la stessa che c’è tra sentirti dire “ho fame” e capire che stai cercando un ristorante aperto in questo momento nel quartiere dove ti trovi.
Detto in modo ancora più diretto: i dati strutturati sono il modo in cui il tuo sito parla alle macchine con precisione.
E le macchine, nel 2026, non sono più solo i motori di ricerca tradizionali. Sono anche i sistemi di intelligenza artificiale, i Large Language Model (LLM), gli agenti IA che rispondono alle domande degli utenti senza nemmeno mostrare un elenco di risultati.
Sistemi come ChatGPT, Perplexity, Google AI Overviews, e una quantità crescente di assistenti verticali che operano in settori specifici.
Il nuovo dataset: finalmente sappiamo chi usa cosa
Il 4 giugno 2026, Schema.org ha annunciato ufficialmente la pubblicazione di un dataset pubblico con statistiche aggregate sull’utilizzo dei suoi termini attraverso il web.

Il progetto è nato dalla collaborazione tra Google e la comunità Schema.org, e l’obiettivo dichiarato è portare trasparenza su come diversi tipi e proprietà vengono effettivamente utilizzati da sviluppatori e publisher a livello globale.
I dati vengono aggiornati ogni mese.
Sono aggregati a livello di dominio, presentati in fasce di popolarità, il che significa che non vengono rivelate informazioni sui singoli siti, ma si può capire con precisione quali markup siano ampiamente adottati e quali siano ancora di nicchia. I file sono disponibili sul repository ufficiale di Schema.org su GitHub, in formato CSV e JSON, e le stesse statistiche vengono ora visualizzate direttamente nelle pagine dei singoli termini su Schema.org.
Ryan Levering di Google, uno degli ingegneri che ha lavorato al progetto, ha spiegato su LinkedIn che Dan Brickley, uno dei padri fondatori di Schema.org, da anni chiede che Google pubblichi statistiche sull’utilizzo dei markup sul web.
Finalmente ho ricevuto un po’ di supporto per finire il progetto e spero che presto arrivino altre cose interessanti. È difficile per la maggior parte dei crawl aperti ottenere la stessa profondità di indice che abbiamo su Google, quindi siamo felici di presentare alcune statistiche di utilizzo su termini schema.org, anche se sono un po’ astratti.
Ryan Levering, Software Engineer di Google
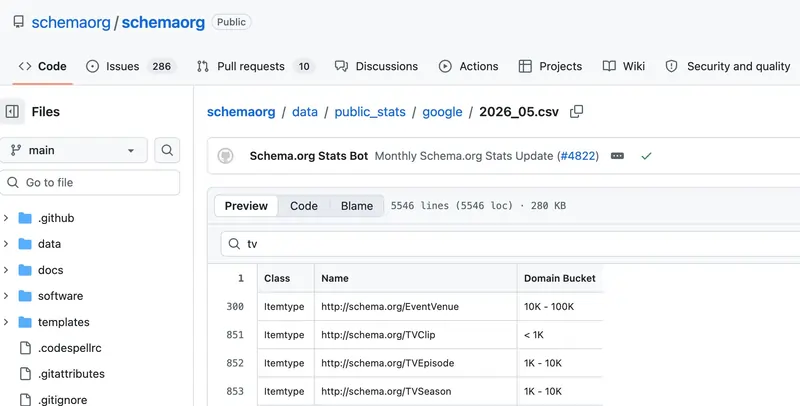
Barry Schwartz, il direttore di Search Engine Roundtable, una delle voci più seguite nel mondo SEO, ha commentato la notizia evidenziando l’esempio più immediato che questi dati offrono: il markup Author è presente su oltre 10 milioni di domini, mentre il markup Event è usato su meno di un milione.
Due tipi di dati strutturati, una differenza di adozione che rivela molto su come il web reale sia strutturato rispetto a quello ideale che gli esperti tecnici immaginavano.
Per cui, se stai decidendo quali markup implementare sul tuo sito e hai risorse limitate, sapere che certi tipi di Schema.org sono adottati su decine di milioni di domini mentre altri faticano a superare poche centinaia di migliaia, ti aiuta a concentrare l’investimento dove il ritorno è più probabile.
Il click non è più l’unico metro di misura
Ma torniamo al punto di partenza. SparkToro, utilizzando i dati di Similarweb, ha pubblicato una ricerca che mostra come il 68,01% delle ricerche su Google negli Stati Uniti, tra gennaio e aprile 2026, si sia concluso senza nessun click verso siti esterni.
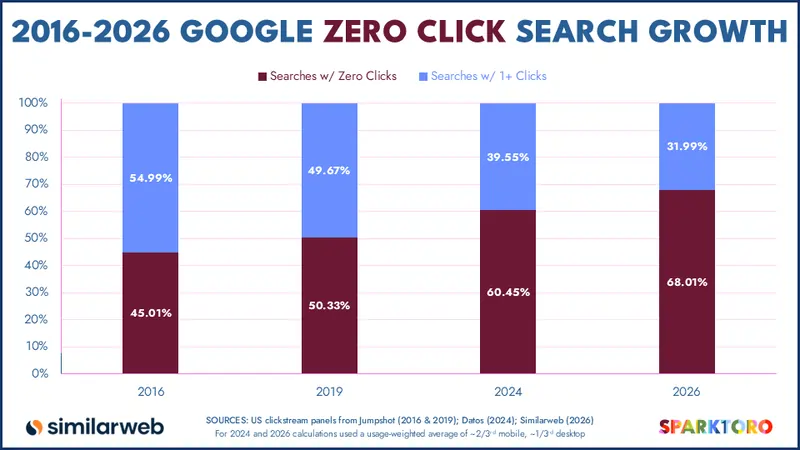
Non c’è da meravigliarsi: si tratta di un trend che si consolida da anni, accelerato dall’introduzione delle AI Overviews di Google, dai pannelli informativi, dalle risposte dirette che il motore di ricerca fornisce prima ancora che tu possa scegliere su cosa cliccare.
La domanda ovvia adesso è: che cosa significa questo per il tuo sito?
Beh, innanzitutto che il click non è più l’unico outcome che conta, come ci ha ricordato anche Amanda King durante la nostra intervista.
Una pagina può ancora essere rilevante e preziosa per il tuo business anche se non riceve visite dirette, a condizione che diventi la fonte che un sistema di intelligenza artificiale usa per costruire la propria risposta.
Che venga citata da ChatGPT.
Che appaia nelle fonti di Perplexity.
Che sia il contenuto da cui un AI Overview di Google estrae le informazioni che mostra all’utente prima dei risultati organici.
Come puoi intuire tutto ciò cambia completamente la logica con cui valutare un contenuto online. Non è più solo “quante persone cliccano su questo” ma “questo contenuto è abbastanza preciso, strutturato e verificabile da essere usato come fonte affidabile da un sistema IA?”
È una differenza sottile ma con implicazioni pratiche enormi.
Gli agenti IA leggono il tuo sito: sei pronto?
C’è un dato di Semrush che completa il quadro in modo quasi disturbante.
Il traffico generato da bot, agenti AI e crawler supera ormai il traffico umano su molti segmenti del web.
Il tuo contenuto, in altre parole, viene già letto da macchine che agiscono per conto di persone. Il tuo sito ha due pubblici distinti, e probabilmente stai ottimizzando solo per uno dei due.
Questo cambia il lavoro tecnico di chi si occupa di SEO e di chi costruisce contenuti per il web. Le pagine devono essere abbastanza chiare da permettere un’estrazione precisa da parte di sistemi automatizzati, e abbastanza autorevoli e verificabili da guadagnarsi la fiducia di un modello linguistico che deve decidere se quella fonte vale una citazione o no.
I dati strutturati, in questo scenario, sono il modo in cui il tuo sito comunica alle macchine non solo cosa contiene, ma cosa significa quello che contiene.
Che tu venda prodotti, offra servizi professionali, pubblichi contenuti editoriali o gestisca un catalogo di eventi, esiste un vocabolario Schema.org pensato per rendere il tuo contenuto comprensibile non solo agli esseri umani, ma anche agli agenti IA che sempre più spesso agiscono come intermediari tra l’informazione e chi la cerca.
Per questo oggi un’agenzia SEO/GEO lavora per aumentare la visibilità anche nei motori di risposta basati sull’intelligenza artificiale, strutturando i contenuti affinché possano essere interpretati correttamente, citati come fonti affidabili e trasformati in risposte dagli assistenti IA.
Le ontologie non sono roba da filosofi: sono il futuro del business online
C’è un livello di analisi più profondo, che richiede un piccolo sforzo di astrazione ma che vale la pena fare perché chiarisce verso dove sta andando tutto questo.
Andrea Volpini, CEO di WordLift e ricercatore nel campo dell’intelligenza artificiale applicata al web, ha pubblicato il 5 giugno 2026 un articolo tecnico dal titolo “Ontologies for the Agentic Web” che mette a fuoco qualcosa di importante.
Anche se alle superiori avevi il debito in filosofia, cerco di essere più chiaro possibile…
Le ontologie sono modelli formali che organizzano la conoscenza in modo strutturato. Fin qui ci siamo, giusto?
Questa è la descrizione tecnica di quello che fa Schema.org quando definisce che un “Prodotto” ha un “Prezzo”, un “Produttore”, una “Descrizione” e una “Valutazione”, e che queste proprietà hanno relazioni precise tra loro. Il vocabolario di Schema.org è, tecnicamente parlando, un’ontologia.
Semplificata e pragmatica, ma un’ontologia.
Volpini sostiene che questi strumenti, che nel decennio scorso servivano principalmente a rendere i dati comprensibili ai motori di ricerca, stanno diventando qualcosa di diverso nell’era degli agenti IA.
Servono agli agenti artificiali per interpretare il significato delle informazioni, recuperare dati affidabili, mantenere memoria del contesto di una conversazione, prendere decisioni più accurate e, quando necessario, agire in autonomia.
Il punto su cui Volpini si sofferma è che Schema.org rappresenta solo uno strato di un sistema molto più complesso che stiamo costruendo in tempo reale.
Un sistema dove la struttura formale dei dati, la capacità di validarli, di tracciarli nel tempo, di recuperarli in modo efficiente e di usarli come memoria persistente per i sistemi IA diventa il vero asset competitivo, come Andrea ci aveva già anticipato nel corso della nostra chiacchierata su SEO Confidential.
Non il contenuto grezzo, ma il contenuto strutturato, verificabile, collegato a entità e relazioni precise.
Cosa cambia concretamente per te e il tuo sito?
Tradotto in linguaggio pratico, per chi gestisce un sito con l’obiettivo di portare clienti e generare ricavi, questo scenario suggerisce alcune riflessioni molto concrete.
La prima riguarda la qualità delle informazioni che il tuo sito veicola.
Un contenuto vago, generico, scritto per sembrare autorevole senza esserlo davvero, aveva già i suoi limiti nell’era del posizionamento organico tradizionale. Nell’era degli agenti IA che selezionano le fonti da citare, quel tipo di contenuto è semplicemente inutile. I sistemi IA tendono a preferire fonti con dati verificabili, affermazioni precise, struttura chiara.
Se vuoi essere citato, devi avere qualcosa di preciso da dire.
La seconda riguarda i dati strutturati veri e propri. Il nuovo dataset di Schema.org ti permette di capire quali tipi di markup siano già diffusi e quali siano ancora scarsamente adottati.
Se vendi prodotti online e non hai ancora implementato il markup Schema per Product, Offer e Review, stai rinunciando a un canale di comunicazione con i sistemi che sempre più spesso fungono da filtro tra l’utente e i contenuti.
Se gestisci un’attività locale e non usi il markup per LocalBusiness, stai lasciando a metà una conversazione che le macchine vorrebbero avere con te.
La terza, forse la più sottile, riguarda la coerenza tra quello che dici e come lo dici strutturalmente.
Un sito che dichiara di essere esperto in un settore, ma i cui dati strutturati non corrispondono a questa autorevolezza, invia segnali contraddittori. Schema.org ti permette di dichiarare esplicitamente chi sei, cosa fai, chi lavora con te, quali servizi offri, in quale area geografica operi, con quale credibilità.
Il dataset come specchio del web reale
Torniamo un momento ai numeri del nuovo dataset, perché meritano attenzione. Il fatto che il markup Author sia presente su oltre 10 milioni di domini mentre Event sia sotto il milione racconta qualcosa di preciso sulla loro diffusione…
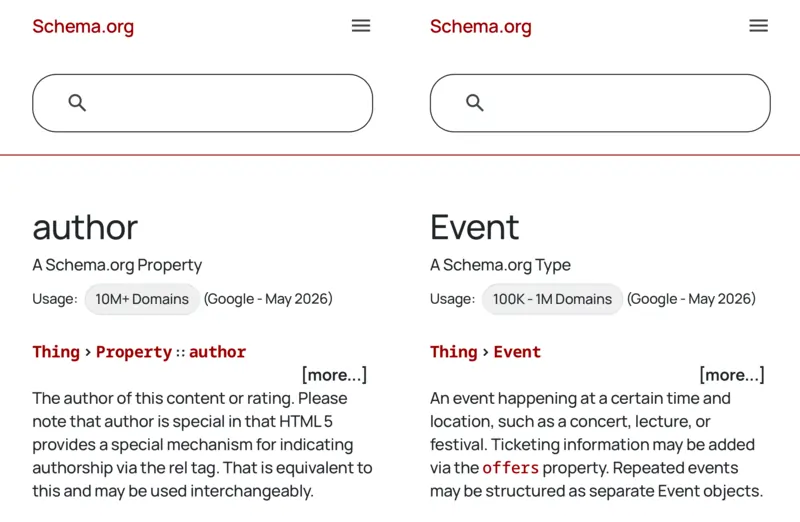
I siti di contenuto editoriale, quelli che producono articoli, guide e risorse informative, si sono adattati prima e meglio agli standard strutturati. I siti focalizzati su eventi, che potrebbero beneficiarne enormemente per la visibilità sulle piattaforme IA, restano largamente indietro.
È una fotografia, non un giudizio. Ma è una fotografia che ti permette di capire dove ci sono spazi ancora aperti.
Se organizzi eventi e vuoi che i sistemi IA capiscano esattamente cosa stai offrendo, quando, dove e a chi, il markup Event di Schema.org è ancora largamente sottoutilizzato dai tuoi competitor. Se sei un professionista che vuole essere riconosciuto come fonte autorevole su un argomento, il markup Author è già diffusissimo, il che significa che è atteso e che la sua assenza è una lacuna.
Questa è esattamente la logica con cui il dataset va usato: non come ranking di cosa sia importante in astratto, ma come mappa di dove si trovano le opportunità concrete per chi vuole essere trovato, citato e riconosciuto come fonte affidabile nell’ecosistema in cui l’intelligenza artificiale sta diventando il primo intermediario tra la domanda e l’offerta di informazioni.
Da fonte passiva a risorsa attiva per i sistemi IA
C’è un cambio di paradigma che vale la pena ricordarti prima di chiudere.
Per anni, la logica del web era essenzialmente passiva: costruisci un buon sito, ottimizzalo tecnicamente, pubblica contenuti rilevanti, e Google ti troverà e ti manderà visitatori. Tu eri il destinatario di un flusso di traffico che Google controllava.
Nell’era degli agenti IA, la logica si fa più attiva e più sfumata.
Non si tratta solo di essere trovati, ma di essere selezionati come fonte, come è emerso anche nella nostra discussione con il SEO Peter Rota.
E per essere selezionati come fonte, devi essere comprensibile, verificabile, strutturato in modo coerente, e sufficientemente preciso da essere utile a un sistema che deve costruire una risposta accurata senza poter consultare ogni volta tutta la pagina che hai scritto.
I dati strutturati, in questo senso, aiutano motori di ricerca e sistemi di intelligenza artificiale a comprendere meglio un sito, le sue entità e le informazioni che possono utilizzare come fonte nelle loro risposte. Come tenersi aggiornati sul vocabolario che questi sistemi comprendono meglio, come implementarlo correttamente, come verificare che stia funzionando: sono domande che chiunque voglia restare competitivo online nel 2026 dovrebbe iniziare a porsi con regolarità.
È proprio su questi aspetti che, negli ultimi anni, si concentra una parte sempre più importante del mio lavoro come consulente SEO/GEO.
Analizzo il modo in cui motori di ricerca (e di risposta), assistenti IA e modelli linguistici interpretano i contenuti, studio l’evoluzione di Schema.org e dei dati strutturati e aiuto aziende ed editori a organizzare le informazioni affinché possano essere comprese, considerate affidabili e utilizzate come fonte nelle risposte generate dall’intelligenza artificiale.
Il web che parlava alle macchine, e quello che ci lavora insieme
La storia dei dati strutturati sul web è, in fondo, la storia di un tentativo lungo venticinque anni di costruire un linguaggio condiviso tra esseri umani e macchine.
Tim Berners-Lee, uno degli inventori del World Wide Web, sognava già nel 2001 un “web semantico” in cui le informazioni avrebbero avuto significato preciso e le macchine avrebbero potuto ragionare su di esse.
Schema.org, arrivato dieci anni dopo, ha portato quel sogno in una dimensione pragmatica e scalabile.
Oggi quel percorso si incontra con qualcosa di più grande e più veloce: i modelli linguistici di grandi dimensioni, i motori di risposta basati su IA che stanno ridisegnando come le persone cercano informazioni, prendono decisioni e interagiscono con il web.
Andrea Volpini, nel suo articolo, usa una metafora precisa: nell’era del web semantico, le ontologie aiutavano le macchine a capire il mondo. Nell’era degli agenti IA, aiutano le macchine ad agire nel mondo senza perdere il senso di quello che stanno facendo.
Per te, che gestisci un sito con l’obiettivo di portare clienti e generare business, questa evoluzione è un’opportunità concreta di differenziarti in un momento in cui molti stanno ancora guardando i vecchi indicatori, i click, le posizioni in SERP, il traffico organico, senza capire che il campo da gioco si è allargato e che si può giocare anche su superfici che non esistevano tre anni fa.
Il punto di partenza è semplice: capire quali dati strutturati siano più rilevanti per il tuo settore, verificare cosa stai già usando e cosa ti manca, e consultare il dataset pubblico di Schema.org per sapere dove ti trovi rispetto al resto del web.
Non è un lavoro di una settimana, ma è il tipo di investimento che costruisce valore nel tempo, indipendentemente da quale motore di ricerca o sistema IA sarà dominante tra due anni.
Le macchine cambieranno.
Il linguaggio con cui comunichi con loro, se è ben strutturato e preciso, resterà.
Se vuoi rendere la tua azienda più visibile anche nei sistemi di intelligenza artificiale, contatta la nostra agenzia SEO/GEO: ti aiuteremo a costruire una strategia che renda i tuoi contenuti comprensibili, autorevoli e sempre più presenti nelle risposte generate dall’IA.
Il nuovo dataset pubblico di Schema.org: domande frequenti
Che cos’è Schema.org e perché è importante per la visibilità online?
Schema.org è un vocabolario condiviso che permette ai siti web di descrivere in modo strutturato il significato dei propri contenuti. Grazie ai dati strutturati, motori di ricerca e sistemi di intelligenza artificiale comprendono meglio persone, prodotti, servizi, eventi e altre informazioni, aumentando le possibilità che il sito venga utilizzato come fonte nelle risposte generate dall’IA.
Che cos’è il nuovo dataset pubblico di Schema.org?
Il nuovo dataset pubblico di Schema.org raccoglie statistiche aggregate sull’utilizzo dei diversi tipi e proprietà dei dati strutturati sul web. Aggiornato ogni mese, permette di capire quali markup sono più diffusi, confrontare la propria implementazione con le tendenze del settore e individuare opportunità di miglioramento.
Perché oggi i dati strutturati sono importanti anche per l’intelligenza artificiale?
I sistemi di intelligenza artificiale utilizzano sempre più spesso i dati strutturati per interpretare correttamente i contenuti di un sito e individuare fonti affidabili. Una corretta implementazione di Schema.org aiuta motori di ricerca, assistenti IA e modelli linguistici a comprendere le informazioni, favorendo la possibilità che vengano citate nelle risposte generate automaticamente.

Ci danno il manuale per diventare tutti uguali, così sceglieranno il più omologato di noi.
Ci consegnano le chiavi della nostra stessa irrilevanza, un manuale per diventare cibo predigerito per l’algoritmo. E noi tutti in fila, pronti a ringraziare per la ricetta.
@Alberto Parisi Se il menù è uguale per tutti, vince chi diventa il piatto gourmet.
La chiamano resa, io la chiamo selezione. I dati strutturati sono il nuovo spartiacque. Chi non si adegua, diventa semplicemente un fossile digitale.
Un nuovo standard per separare i professionisti dai dilettanti. Chi si lamenta ha già perso. È solo un altro filtro per qualificare il traffico e far arrivare i clienti giusti. Meglio così, si lavora con meno rumore di fondo.
Fantastico. Ennesimo giro di giostra per accontentare un algoritmo. Prima Google, ora le IA. E noi strategist a correre dietro a righe di codice. A me questa roba mette solo una gran agitazione.
In pratica, per diventare una fonte autorevole bisogna prima superare un esame di conformità con le IA, che poi decideranno cosa è utile per gli umani. Una bella inversione di priorità, non c’è che dire.
Isabella Sorrentino, la chiamano evoluzione, ma a me pare una resa incondizionata. Ormai il nostro lavoro consiste nel diventare i diligenti segretari delle macchine, sperando ci concedano la grazia di essere citati. Che parabola discendente.
Un dataset pubblico. In pratica, la nuova checklist per piacere alle macchine. Prevedo un’ondata di copia-incolla di markup, con la qualità che resta un’opinione. È la solita corsa a chi si adegua per primo, nient’altro di nuovo sotto il sole.