Primary Bias: l’intelligenza artificiale ha un pregiudizio sul tuo brand e tu potresti partire svantaggiato
📌 TAKE AWAYS
L'intelligenza artificiale sviluppa una percezione dei brand già durante l'addestramento, influenzando quali aziende vengono citate nelle risposte di ChatGPT, Gemini e Google AI Overview.
Comprendere il Primary Bias e adottare una strategia SEO/GEO mirata è sempre più importante per migliorare autorevolezza, visibilità e reputazione nei sistemi di IA.
Ricordo che un mio professore delle medie aveva un forte pregiudizio sul mio compagno di banco.
Qualche anno prima aveva avuto in classe il fratello maggiore che non era propriamente uno studente modello. Diciamocelo fuori dai denti: era un vero casinista.
Per questo motivo il prof. guardava il mio compagno come a dire: “Ti conosco già, so benissimo chi sei…”
Non importava quanto fosse bravo, quanto si impegnasse per fargli cambiare idea. L’etichetta era già lì, appiccicata in fronte. Ma poi, happy end: dopo il primo quadrimestre, interrogazione dopo interrogazione, il mio amico dimostrò il suo valore fino a diventare il preferito del prof.!
Ecco, devi sapere che i pregiudizi non riguardano solo gli esseri umani.
I modelli di intelligenza artificiale funzionano esattamente così. Hanno già studiato miliardi di testi prima che tu arrivassi. Si sono già fatti un’idea di chi è autorevole nel tuo settore, chi merita di essere citato, chi no. E quella percezione non la cambiano facilmente, proprio come quel mio vecchio insegnante.
Il Primary Bias è già al lavoro. E se hai un sito, un e-commerce o un brand che vuoi far crescere, sta lavorando anche su di te, in questo momento, mentre leggi.
Non puoi riscrivere quello che il modello ha già imparato su di te. Quella percezione è codificata nel training e non si tocca dall’esterno.
Quello che puoi fare, però, è lavorare sui contenuti e sui segnali che alimenteranno i prossimi aggiornamenti del modello. I modelli si aggiornano, le associazioni evolvono. Ogni fine-tuning è un’occasione per spostarti nella direzione giusta, a patto di averci lavorato in anticipo.
La classifica invisibile che decide chi esiste
Partiamo da un esempio concreto, perché i concetti astratti stufano in fretta.
Dan Petrovic, fondatore di DEJAN, una delle agenzie SEO più avanzate nel campo dell’intelligenza artificiale, ha pubblicato a giugno 2026 un’analisi molto precisa su come funziona il “ranking” nei motori di ricerca basati su IA.
Ha preso una query semplice: “best tablets 2026 for entertainment”. Il modello ha risposto con una lista. Prima Apple iPad Pro M5, poi Samsung Galaxy Tab S11 Ultra, poi OnePlus.
Sembra banale, no?
Ma Petrovic ha fatto qualcosa di interessante: ha preso quella risposta e l’ha scomposta, assegnando a ogni brand una posizione numerica in base all’ordine in cui compariva nel testo.
Così facendo ha dimostrato che anche in assenza dei tradizionali dieci link blu, esiste un ranking preciso e misurabile, costruito dall’ordine in cui le entità vengono citate nel testo generativo.
Chi appare per primo ha più visibilità, più autorevolezza percepita, più possibilità di essere ricordato.
E il problema (e la grande opportunità), per te, è che quell’ordine non è casuale.
Attenzione, so bene cosa potresti obiettare: i modelli IA non sono deterministici, non generano mai la stessa identica risposta!
È verissimo: se ripeti il prompt, le parole e le frasi cambieranno. Eppure, a causa del loro bias interno, la probabilità che l’IA citi lo stesso brand al primo posto in otto conversazioni su dieci resta altissima.
Come si diventa la prima risposta di un’IA?
I modelli di linguaggio come Gemini, ChatGPT o Claude non costruiscono le risposte dal nulla.
Usano due cose: la loro memoria parametrica, cioè tutto quello che hanno assorbito durante l’addestramento su miliardi di testi, e le fonti esterne che recuperano in tempo reale (nel caso dei sistemi con grounding, come Google AI Overview o Perplexity).
Il punto critico è che non tutte le fonti vengono trattate allo stesso modo.
Qui entra in scena il Primary Bias: la predisposizione interna del modello a considerare un brand, un’entità o una fonte più rilevante di altri per uno specifico argomento. Se un’IA ha “visto” durante il training milioni di testi che associano il tuo concorrente a una certa categoria di prodotti, quella percezione è già codificata.
È come se il modello avesse già un’opinione su di te, formata prima ancora che tu abbia detto una parola.
Tutto questo influenza direttamente il Selection Rate (SR): ovvero la frequenza con cui un modello seleziona una determinata fonte o un determinato brand tra tutti quelli disponibili per costruire una risposta.
La formula è semplice: SR = (numero di selezioni / totale risultati disponibili) × 100.
Ma le implicazioni sono tutt’altro che semplici come ti ho scritto anche qui.
Il Selection Rate è il nuovo CTR, ma con un colpo di scena
Nella SEO tradizionale, il Click-Through Rate misura quante persone cliccano sul tuo link rispetto a quante lo vedono. È una metrica di comportamento umano.
Il Selection Rate misura invece una scelta che fa l’IA per conto tuo, senza che l’utente lo sappia e senza che tu possa influenzarla direttamente in tempo reale.
Duane Forrester, veterano del settore e autore di studi sull’impatto dei bias nei sistemi di ricerca (lo avevamo intervistato qui), descrive questo fenomeno come un circolo che tende ad autoalimentarsi: un brand con un alto SR viene citato spesso, ottiene più visibilità, viene percepito come più autorevole, e quindi viene selezionato ancora più spesso.
I ricercatori hanno persino coniato un termine per questo meccanismo: neural howlround, mutuato dall’acustica, dove un segnale amplificato ritorna al sistema e si autorinforza creando un loop difficile da interrompere.
Uno studio del 2025 sul “Neural howlround” di Seth Drake ha descritto come certi input altamente ponderati nei modelli LLM possano diventare così radicati da resistere anche a nuovi dati di training o prompt in tempo reale.
Tradotto: se sei già “dentro” al modello con una buona posizione, è difficile scalzarti.
Se sei fuori, è difficile entrare.
Il caso Owayo: quando il bias si vede con i numeri
Petrovic ha usato uno strumento di analisi sviluppato dalla sua agenzia, AI Rank, per misurare il Primary Bias su un caso reale. Il brand in questione è Owayo, un’azienda di abbigliamento sportivo personalizzato.
Il modello di Google lo associa con alta confidenza a query come “custom cycling jerseys” nel mercato americano. Questo significa che quando Owayo viene fornito come fonte nel corpus di grounding di un sistema IA, ha una probabilità molto alta di essere selezionato nella risposta finale.
Un competitor come Albion Fit, invece, risulta rilevante per alcune query correlate ma con una confidenza interna del modello molto più bassa per le stesse query specifiche.
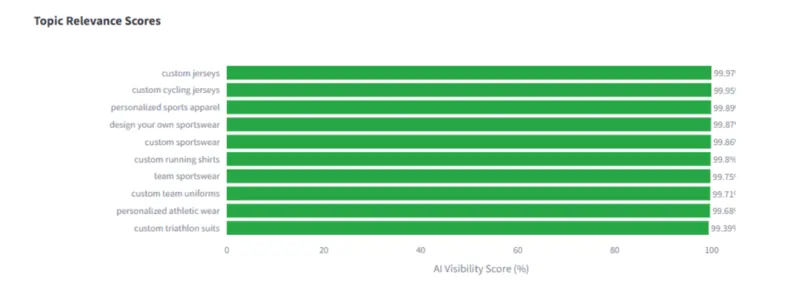
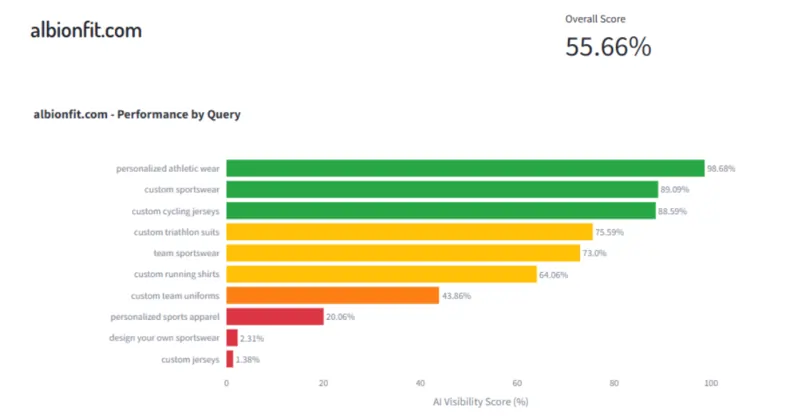
Risultato: a parità di qualità del prodotto e del sito, Owayo viene citato e Albion Fit no, o viene citato molto meno spesso.
Non perché Owayo abbia fatto qualcosa di straordinario nell’ultimo mese. Ma perché nel tempo ha accumulato un’associazione più forte e coerente con quella categoria nella mente del modello.
Questo dovrebbe farti riflettere su quanto tempo ci voglia per costruire quella percezione, e quanto costi non averla.
Tre-sei mesi per un aggiornamento: la finestra che devi sfruttare
Una domanda che sento spesso è: “ma se voglio migliorare la mia posizione nei modelli IA, quanto ci vuole?”
La risposta di Petrovic è precisa: per i fine-tuning minori e i sub-release, tra tre e sei mesi. Per i major release annuali dei modelli, circa un anno.
Non è poco. Ma è anche meno di quanto possa sembrare, se hai già iniziato a lavorarci.
I modelli continuano ad aggiornarsi. Le associazioni parametriche evolvono. I contenuti che pubblichi oggi, strutturati in modo da essere recuperati e citati dall’IA, possono influenzare la percezione interna del modello nel prossimo ciclo di fine-tuning.
Il lavoro SEO classico, quello on-page e off-page che conosci già, ha ancora un ruolo: creare contenuti autorevoli, ben strutturati, citati da fonti credibili.
Ma ora ha un destinatario in più. Non solo Google, non solo il lettore umano.
Anche il modello che domani deciderà se citarti o ignorarti.
La “credibility illusion”: la disinformazione che sembra vera
Fin qui abbiamo parlato di come diventare più visibili. Adesso parliamo di un rischio speculare, e forse più insidioso: come puoi diventare invisibile o peggio, mal rappresentato, senza averlo cercato.
Una ricerca firmata da Zhou et al., dal titolo “Synthetic Lies: Understanding AI-Generated Misinformation and Evaluating Algorithmic and Human Solutions” mostra qualcosa di preoccupante: l’IA genera disinformazione in modo più persuasivo degli esseri umani.
Non perché sia più intelligente nel mentire, ma perché è bravissima a imitare i segnali superficiali dell’autorevolezza. Tono professionale, struttura chiara, citazioni apparenti, sicurezza espositiva. Quello che i ricercatori chiamano “credibility illusion“, l’illusione di credibilità.
Il meccanismo funziona così: se nel tuo settore circolano falsi miti ripetuti su decine di siti, il modello li ha appresi durante il training. Non li distingue dal resto. E quando li ripresenta, lo fa con la stessa sicurezza di una fonte autorevole.
Un cliente che chiede all’IA “il prodotto X è sicuro?” potrebbe ricevere una risposta sbagliata formulata come un parere di esperto.
Uno studio del MIT del 2025 ha aggiunto un dettaglio tecnico importante: anche l’ordine dei documenti forniti in input a un LLM cambia l’output. Non è solo una questione di quali contenuti esistono, ma di come vengono presentati al modello.
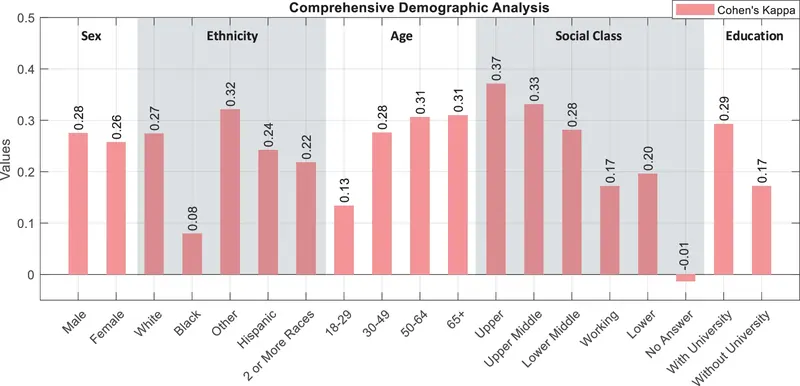
Una ricerca pubblicata nel 2025 su PNAS dimostra inoltre che anche i grandi modelli linguistici progettati per essere imparziali continuano a manifestare bias impliciti.
Sebbene GPT-4 e altri LLM evitino affermazioni apertamente discriminatorie, mantengono associazioni stereotipate apprese durante il preaddestramento. Utilizzando nuovi test ispirati alla psicologia, i ricercatori hanno osservato che i modelli tendono ad associare uomini alle discipline scientifiche, donne alle materie umanistiche e candidati con nomi occidentali a posizioni dirigenziali rispetto a persone appartenenti a minoranze etniche.
Questi pregiudizi emergono soprattutto quando l’IA deve confrontare due alternative e prendere una decisione. Secondo gli autori, l’allineamento riduce i bias espliciti, ma non elimina quelli profondamente radicati.
Il bias come arma: lo scenario che nessuno vuole ammettere
Qui arriviamo al punto più scomodo, quello che il SEO Duane Forrester chiama “attack vector”.
Cosa succede se un tuo concorrente inizia a seminare contenuti online che descrivono la tua azienda in una certa luce, senza nominarti direttamente, ma con abbastanza coerenza e distribuzione da influenzare la percezione del modello?
Non servono violazioni legali. Non serve una campagna di diffamazione esplicita.
I modelli di linguaggio, come precisa Forrester, sono molto bravi a dedurre un brand da descrizioni indirette. Logo, tratti distintivi, settore, tono. Una narrativa distribuita su abbastanza siti, in abbastanza variazioni, può diventare “consenso” agli occhi del modello.
E quel consenso, una volta codificato, è difficile da correggere.
È la logica stessa del training dei modelli applicata in senso strategico. Una “whispering campaign” online non ha bisogno di diventare virale per avere effetto. Deve solo essere abbastanza diffusa da sembrare un pattern.
Cosa fare per prevenire la disinformazione e conquistare le IA?
Se hai un sito, un brand, un business online, ci sono cose che puoi iniziare a fare subito per migliorare la tua reputazione nei sistemi IA.
La prima è costruire quella che il SEO Chester Beard chiama “expertise density”: contenuti densi, precisi, facilmente recuperabili dall’IA, che rispondano alle domande che i tuoi clienti fanno ai chatbot. Sezioni FAQ dettagliate, spiegazioni approfondite dei fondamentali del tuo settore, segnali chiari di competenza. Quando un’IA cerca informazioni sul tuo settore, deve trovare te, non qualcun altro.
La seconda è smontare proattivamente la disinformazione. Se nel tuo settore circolano miti, affrontali di petto con contenuti dal titolo esplicito: “Mito vs realtà”, “Cosa dicono davvero i dati su X”. Questo serve ai clienti in carne e ossa e al tempo stesso fornisce al modello un’alternativa credibile a ciò che potrebbe avere imparato di sbagliato.
La terza è monitorare come le IA ti rappresentano. Fai domande regolari ai principali chatbot sul tuo settore, sul tuo brand, sui tuoi prodotti.
Cosa dice ChatGPT quando qualcuno chiede di te? Cosa risponde Gemini?
Le risposte ti diranno dove sei posizionato nella percezione del modello e dove devi lavorare, come ti ho scritto qui in questo mio caso studio.
La percezione del modello è il nuovo brand
Il tuo contenuto ora deve piacere a un lettore umano, passare i filtri di Google, e convincere un modello di linguaggio che tu sei la fonte più rilevante per il tuo argomento.
Non sono tre obiettivi in contraddizione. Un contenuto autorevole, ben strutturato, basato su dati reali e scritto per un pubblico specifico soddisfa tutti e tre. Ma richiede consapevolezza.
Richiede di sapere che esiste il Primary Bias, che esiste il Selection Rate, che l’IA ha già un’opinione su di te anche se non te l’ha mai detta.
C’è una frase di Forrester che mi è rimasta in testa:
Se non gestisci attivamente la tua presenza nei sistemi IA, l’IA farà comunque delle scelte su di te. Solo che non saranno scelte che hai controllato.
Duane Forrester
Sostituisci “IA” con “mercato” e hai la stessa regola che vale da sempre nel business. La novità è che il mercato, oggi, include anche dei modelli linguistici che decidono chi citare e chi ignorare, chi è autorevole e chi no, chi esiste nelle risposte e chi scompare nel rumore.
Nel principio, costruire la tua reputazione nei modelli IA non è diverso dal costruire la tua autorità online. Richiede tempo, coerenza, contenuti di qualità, e la consapevolezza che stai parlando anche a interlocutori non umani.
Ma la posta in gioco è la stessa di sempre: visibilità, credibilità, clienti, ricavi.
Il Primary Bias non è un concetto da lasciare ai ricercatori. È il territorio su cui si giocherà buona parte della competizione online nei prossimi anni.
E come sempre, chi capisce le regole del gioco prima degli altri parte con un vantaggio che è molto difficile da colmare.
Se vuoi farti trovare preparato, contatta la nostra agenzia SEO/GEO: lavoriamo insieme per rendere il tuo brand una fonte autorevole per Google, ChatGPT, Gemini e gli altri sistemi di IA.
L’IA ha già un’opinione sulla tua azienda: domande frequenti
Che cos’è il Primary Bias nell’intelligenza artificiale?
Il Primary Bias è la predisposizione di un modello di intelligenza artificiale a considerare alcuni brand, fonti o entità più rilevanti di altri per uno specifico argomento. Questa percezione nasce durante l’addestramento del modello e influenza la probabilità che un’azienda venga citata nelle risposte generate dall’IA.
È possibile modificare il Primary Bias di un modello di intelligenza artificiale?
Non è possibile modificare direttamente il Primary Bias di un modello già addestrato. È però possibile influenzare i futuri aggiornamenti dei modelli creando contenuti autorevoli, ottenendo citazioni da fonti affidabili e rafforzando nel tempo la reputazione digitale del proprio brand.
Perché la SEO è importante anche per ChatGPT, Gemini e Google AI Overview?
I moderni sistemi di intelligenza artificiale utilizzano sia le conoscenze apprese durante l’addestramento sia fonti recuperate in tempo reale attraverso tecniche di grounding. Per questo una strategia SEO e GEO efficace aumenta le probabilità che un brand venga selezionato e citato nelle risposte generate dall’IA.

Chiamatelo ‘Primary Bias’ o come vi pare, ma se il brand non esce è perché ha poco da dire, non certo per colpa dell’algoritmo.