La Reuters e il Time hanno iniziato a bloccare i crawler AI di default: ecco cosa sta cambiando e perché dovresti preoccupartene anche tu
📌 TAKE AWAYS
Reuters e Time hanno iniziato a bloccare di default i crawler AI, consentendo l’accesso solo ai bot autorizzati. La scelta punta a limitare lo scraping gratuito dei contenuti e favorire accordi di licenza, ma apre un dilemma per siti piccoli e medi: proteggere il valore dei contenuti o mantenere visibilità nei motori di risposta AI.
Apri il bar, sistemi il bancone, scegli i chicchi migliori, controlli le macchine e investi sulla formazione del personale. Tutto procede finché non emerge un dettaglio assurdo: ogni giorno qualcuno passa da un ingresso secondario, raccoglie ciò che hai costruito con fatica e lo rivende poco più in là come se fosse suo.
Non una volta, ma ogni giorno.
Per anni.
E il bello è che lo stava facendo con il tuo permesso implicito, perché nessuno aveva mai pensato di mettere una serratura alla porta sul retro.
Ecco, più o meno, quello che sta succedendo tra i grandi editori e le aziende di intelligenza artificiale. E se pensi che questa storia riguardi solo i colossi dell’informazione, stai per scoprire che ti tocca da vicinissimo.
La rivolta dei grandi editori
A maggio 2026, Reuters e Time hanno fatto una cosa apparentemente tecnica ma straordinariamente significativa: hanno invertito la logica di accesso ai loro contenuti per i crawler AI.
Invece di permettere l’ingresso a tutti i bot e bloccare solo quelli sgraditi, come si faceva finora, hanno deciso di bloccare tutto di default e creare una lista di bot approvati che possono accedere. Una “allowlist“, in gergo tecnico.
Una lista degli invitati, per capirci meglio.
Non sono stati i primi. The Atlantic aveva mosso lo stesso passo alla fine del 2025, People Inc. all’inizio del 2026. Ma quando lo fa Reuters, uno dei servizi di informazione più citati al mondo, con accordi di licenza già attivi con Microsoft e Meta, il messaggio diventa difficile da ignorare.
“Abbiamo visto uno squilibrio tra il valore che un editore come Reuters fornisce e il valore che Reuters riceve in cambio”, ha dichiarato Josh London, responsabile di Reuters Professional, a Digiday.
I nostri contenuti costano denaro da produrre. Hanno un valore significativo, e l’accesso a essi non può essere gratis.
Josh London, Reuters
Ma come si è arrivati a questo punto?
Tali contromisure sono eccessive e possono essere perfino controproducenti?

Quanto è grande il problema? Temo tu lo stia sottovalutando…
Per capire la portata di quello che sta succedendo, serve qualche numero concreto.
Il rapporto Tollbit sullo stato dei bot nel terzo e quarto trimestre del 2025 offre dati che lasciano poco spazio all’ottimismo. Nel primo trimestre dell’anno, c’era 1 visita di bot AI ogni 200 visite umane su un sito medio. Entro fine 2025, quel rapporto era diventato 1 a 31.
In meno di dodici mesi, il traffico generato dai crawler AI è esploso di quasi sette volte.
Ma non è solo questione di volume.
È questione di chi sono questi bot e cosa fanno davvero.
Secondo lo stesso rapporto, nel quarto trimestre del 2025 il 30% degli scraping totali effettuati dai bot AI non rispettava le indicazioni esplicite del file robots.txt. Il robots.txt, per chi non lo conosce, è il documento che ogni sito può pubblicare per dire ai crawler cosa possono e non possono fare.
È come mettere un cartello “vietato l’ingresso”.
Beh, trenta su cento lo ignorano direttamente!
People Inc. ha vissuto questa realtà sulla propria pelle in modo plastico. Quando ha fatto il passaggio da una “blocklist”, cioè una lista di bot da bloccare, a una “allowlist”, cioè una lista di bot da ammettere, il numero di agenti bloccati è passato da circa 2.100 a oltre 30.000.
Lindsay Van Kirk, vicepresidente per l’innovazione dell’azienda, ha condiviso questi dati pubblicamente a un evento IAB Tech Lab a fine maggio 2026. Trentamila bot. Di cui la grande maggioranza era completamente sconosciuta e non dichiarava nemmeno la propria identità.
Ci sono aziende là fuori che non si rivelano e lo fanno unicamente a fini di lucro. Qualcuno ti sta rubando il contenuto e lo sta rivendendo. Cosa ne dici ora? Vuoi apparire o no su ChatGPT?
Lindsay Van Kirk, People Inc.
Il robots.txt non basta più (ma non bastava nemmeno prima)
Il file robots.txt è uno strumento che esiste dagli anni Novanta. È nato in un’epoca in cui i crawler erano pochi, identificabili, e generalmente rispettosi delle regole. Funzionava perché c’era un accordo implicito: i motori di ricerca indicizzano i tuoi contenuti, tu appari nei risultati, tutti ci guadagnano.
Quel patto non esiste più, almeno non nelle stesse forme.
Oggi i bot AI “ingurgitano” i tuoi contenuti per addestrare modelli linguistici o per alimentare motori di risposta come ChatGPT o Perplexity, e il ritorno per il sito originale è, nella migliore delle ipotesi, una citazione senza click.
Nella peggiore, nemmeno quella.
Il rapporto Tollbit ha documentato quasi quaranta attori di scraping di terze parti che raccolgono contenuti, li riformattano per uso AI e li rivendono.
(Per scraping si intende proprio questo: l’estrazione automatica di dati e contenuti da un sito web tramite bot, che li “copiano” rapidamente per salvarli o riutilizzarli altrove).
Molti di questi fornitori si vantano apertamente, sui propri siti, di avere strumenti per aggirare le misure di sicurezza e imitare il comportamento umano. Reddit e Google hanno già fatto causa ad alcuni di questi scraper. Google ha dichiarato pubblicamente che le cause legali erano “l’ultima risorsa”, dopo aver esaurito ogni altro strumento tecnico a disposizione.
Pensa a questo: se un’azienda tecnologica da miliardi di dollari e risorse illimitate non riesce a fermare gli scraper con soluzioni puramente tecniche, cosa può fare il titolare di un e-commerce o di un portale di settore da solo, contando unicamente sulle sue forze?
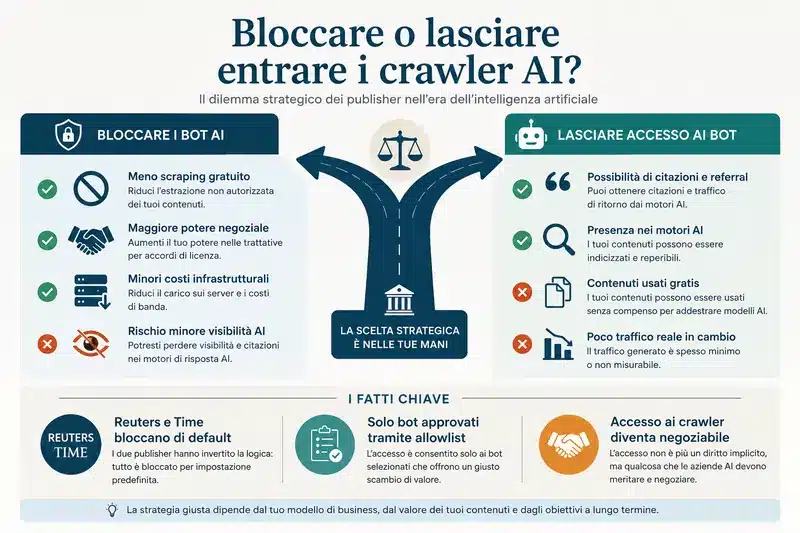
Bloccare i bot per spingerli a negoziare
Allora perché Reuters e Time stanno investendo tempo e risorse in qualcosa che ammettono apertamente essere imperfetto?
La risposta è quasi spiazzante nella sua semplicità: perché l’obiettivo non è bloccare tutto, è rendere lo scraping abbastanza costoso da spingere i grandi player verso i tavoli negoziali.
“Aggiungere due secondi interi di latenza alla maggior parte degli scraper quando implementi un approccio block-all-bots è una cosa davvero buona, anche se poi riescono ad aggirarlo”, ha spiegato Van Kirk. “Ogni scraper che deve pagare una rete di proxy residenziali per accedere al contenuto è un margine che stai sottraendo al suo business. Questo fa bene all’editoria.”
Reuters ha già accordi di licenza con Microsoft e Meta. Alphonse Hardel, responsabile dell’agenzia di Reuters che si occupa di licensing, ha confermato che l’attrito creato dal blocco dei bot ha contribuito a portare queste aziende al tavolo delle trattative.
“Non è vincolante, ed è solo una parte del funnel”, ha detto Hardel a proposito del robots.txt, “ma rafforza il messaggio: se vuoi questo, parliamone, e poi, se vogliamo, possiamo permetterti l’accesso.”
C’è anche un vantaggio economico diretto e immediato.
Bloccare i bot significa smettere di servire richieste che non generano nessun valore.
Secondo Hardel, il risparmio sui costi di infrastruttura è stato “abbastanza alto da avere un impatto positivo sui costi di gestione del sito”, al punto da coprire quasi per intero il costo del vendor specializzato nel bot-blocking.
E il traffico umano?
Non è cambiato di una virgola!
A quanto pare, Reuters non ha perso visitatori reali…
Chi controlla la lista degli ammessi?
Ok, sembra tutto molto lineare, ma come decide Reuters quali bot meritano un posto nella lista degli approvati?
Semplice: ogni bot deve offrire un “fair value exchange”, uno scambio di valore equo. Questo scambio si articola in quattro categorie: licenza a pagamento, traffico in entrata, supporto al funzionamento del sito, e supporto alla monetizzazione.
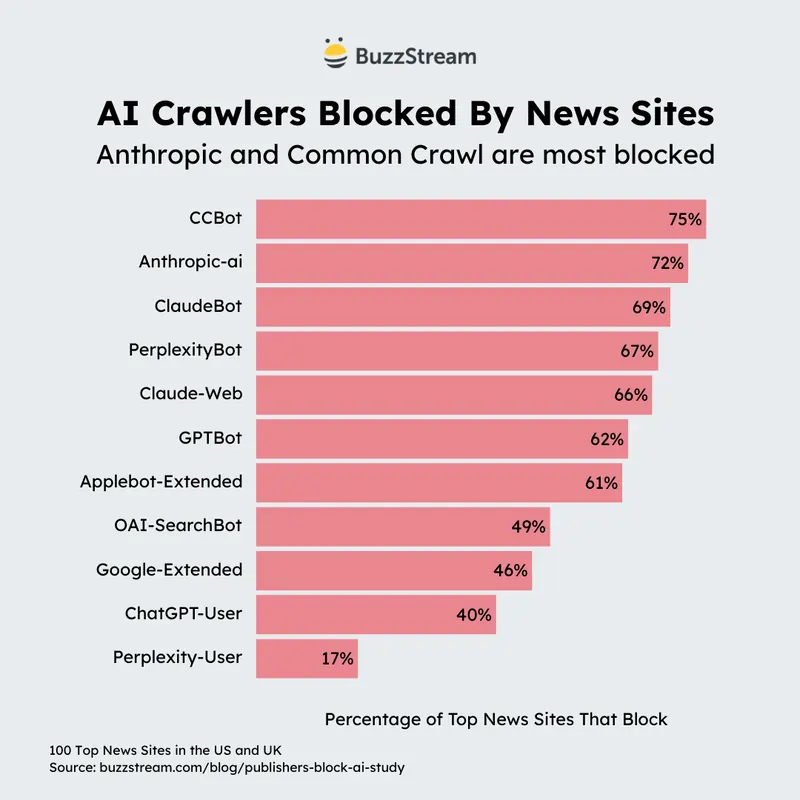
Il risultato è visibile nel file robots.txt pubblico di Reuters, che elenca come approvati i crawler di Amazon, Google, Bing/Microsoft, Yahoo e il bot di ricerca di OpenAI, bloccando tutti gli altri dalla maggior parte del sito.
Non è un caso che Google e Bing siano in lista: portano ancora, oggi, la stragrande maggioranza del traffico organico. Non ammetterli, sarai d’accordo anche tu, sarebbe un suicidio commerciale.
Time, dal canto suo, ha scelto di affidarsi a ScalePost per gestire i bot e ha costruito una lista di circa 70 agenti approvati.
Il COO Mark Howard ha spiegato che il volume crescente di traffico bot, unito all’elevata autorità di dominio percepita dai sistemi AI, ha un valore concreto che l’azienda intende monetizzare, anche attraverso prodotti commerciali di GEO insights venduti ai brand clienti.
“Non è un approccio da impostare e dimenticare”, ha sottolineato Josh London.
È qualcosa che richiede costante attenzione, man mano che il settore e i bot stessi evolvono. Il valore dei contenuti è qualcosa che ignoriamo a nostro rischio e pericolo, specialmente mentre l’AI cresce.
Josh London, Reuters
La forza dei numeri e la coalizione che si sta formando
Un singolo editore che blocca i bot è facile da ignorare, starai pensando.
Ma trentasei editori che lo fanno insieme sono una storia diversa, non credi?
La SPUR Coalition, un gruppo di publisher fondato all’inizio del 2026 con alcune delle principali organizzazioni editoriali, ha aggiunto 30 nuovi membri a maggio, arrivando a 36 organizzazioni. L’obiettivo è costruire standard tecnici condivisi per il licensing dei contenuti e la protezione dallo scraping.
L’IAB Tech Lab ha pubblicato a maggio 2026 una guida dettagliata al bot-blocking per aiutare i proprietari di siti, mettendo in guardia soprattutto sui rischi di implementazioni frettolose.
Van Kirk stessa ha ricordato con ironia che quando People Inc. ha fatto il passaggio all’allowlist, ha accidentalmente bloccato tutte le proprie email di syndication per circa cinque minuti, perché il sistema di invio verificava i link in tempo reale prima di spedire. Piccoli errori con grandi conseguenze.
Pensa che BuzzStream ha analizzato i dati robots.txt dei principali siti di notizie scoprendo che il 79% dei maggiori publisher bloccava già almeno un bot di addestramento AI.
Insomma, il trend è chiarissimo e la direzione sembra sia una sola.
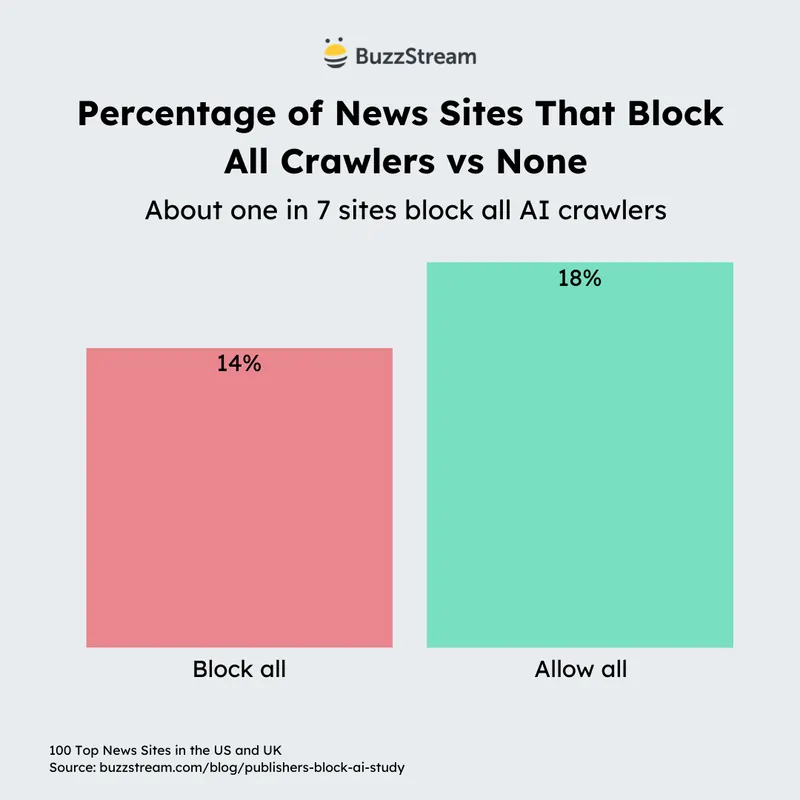
Il click-through che scompare: il dato che nessuno vuole guardare
C’è un numero nel rapporto Tollbit che dovrebbe essere stampato e incorniciato sopra la scrivania di chiunque lavori con contenuti online.
I siti senza accordi diretti con le aziende AI hanno visto il loro tasso di click-through dalle piattaforme AI crollare quasi di tre volte nel corso del 2025: dallo 0,8% nel secondo trimestre allo 0,27% a fine anno.
Già lo 0,8% era un numero sconfortante. Ma lo 0,27% è quasi invisibile.
Significa che su 1.000 volte in cui ChatGPT o Perplexity citano o utilizzano i tuoi contenuti per rispondere a un utente, meno di tre utenti cliccano per visitare il tuo sito.
E la parte più amara?
Anche i siti che hanno stipulato accordi di licenza diretti con le aziende AI non se la sono passata bene: il loro tasso di click-through è sceso addirittura di 6,5 volte nel corso del 2025, dall’8,8% del primo trimestre all’1,33% a fine anno.
Come vedi, gli accordi di licenza sembrano non proteggere affatto dalla progressiva riduzione del traffico referral.
Detto in altro modo: l’AI sta imparando a rispondere sempre meglio senza che l’utente abbia bisogno di andare a vedere la fonte.
E questo, per chi vive di traffico, è un problema strutturale.
Cosa significa tutto questo per te?
Arriviamo ora al punto che ti interessa più da vicino. Hai un sito, ci lavori sopra, ci investi tempo e denaro, e vuoi sapere se e come questa storia ti riguarda.
La risposta onesta è: dipende da chi sei.
Se gestisci un piccolo o medio sito di contenuti, un portale di settore, un blog professionale, un e-commerce con contenuti originali, ovviamente ti trovi in una posizione molto diversa da quella di Reuters.
Non hai un ufficio legale dedicato, non hai accordi con Microsoft, e probabilmente non hai le risorse per monitorare 30.000 bot al giorno. Ma hai comunque delle scelte da fare, e farle con consapevolezza vale molto più che ignorare il problema.
Il punto di partenza più utile sarebbe distinguere tra due tipi di crawler AI che fanno cose molto diverse.
I bot di addestramento, come GPTBot di OpenAI o CCBot di Common Crawl, raccolgono i tuoi contenuti per migliorare i modelli linguistici futuri.
Non ti mandano traffico.
Non ti citano.
Ti usano e vanno.
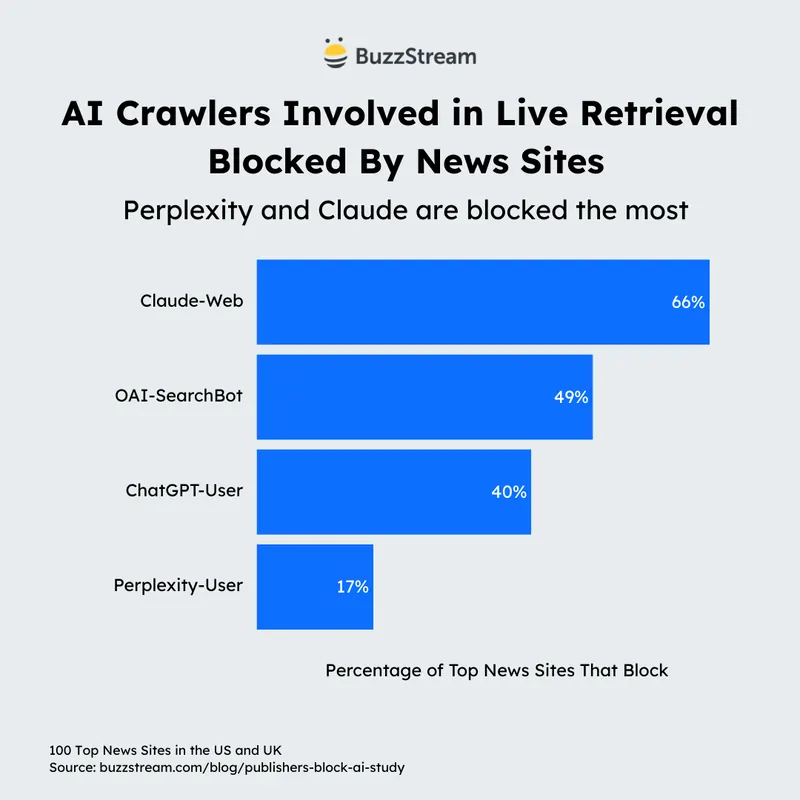
I bot di ricerca, invece, come OAI-SearchBot o PerplexityBot, alimentano motori di risposta che citano le fonti e, almeno in teoria, inviano utenti verso i siti originali.
Trattarli allo stesso modo sarebbe come confondere chi ti ruba il portafoglio con chi ti fa pubblicità.
Per un sito che non ha il potere contrattuale del New York Times, la via più equilibrata sarebbe quella che si potrebbe chiamare “selettività prudente”: bloccare i crawler di puro addestramento e mantenere aperto l’accesso ai bot di ricerca, almeno finché questi continuano a portare qualcosa in cambio.
Nel robots.txt, per esempio, si possono inserire istruzioni specifiche per GPTBot e CCBot, bloccandoli completamente, mentre si lascia accesso a OAI-SearchBot.
C’è un dettaglio tecnico che vale la pena conoscere: Google ha separato il suo bot di indicizzazione tradizionale, Googlebot, dal suo bot AI dedicato, Google-Extended.
Fai attenzione, perché bloccare il secondo non incide sul posizionamento in Google Search.
È una delle poche notizie davvero buone in questa storia, perché significa che puoi proteggere i tuoi contenuti dall’uso per l’addestramento AI senza sacrificare la visibilità sui motori di ricerca classici, che oggi portano ancora la grande maggioranza del traffico organico.
Bloccare tutto, d’altro canto, potrebbe diventare un errore strategico nel medio termine.
Man mano che la ricerca si sposta verso gli assistenti AI, non essere leggibili da questi sistemi significa semplicemente non esistere per una fetta crescente di utenti.
Per chi non può negoziare licenze milionarie, il traffico in entrata rimane la moneta principale. Ed essere citati con un link cliccabile in una risposta di ChatGPT, per quanto raro, vale ancora qualcosa.
Il valore che nessuno vuole pagare, e cosa puoi fare adesso
La vera questione che questa storia solleva è economica.
I contenuti costano.
Un articolo ben scritto, una guida approfondita, una ricerca originale richiedono tempo, competenza, infrastruttura. Le aziende AI hanno costruito prodotti da miliardi di dollari usando questi contenuti come materia prima.
Il conto non è ancora stato presentato, o meglio, lo si sta presentando adesso…
Reuters, Time, The Atlantic e People Inc. stanno tentando di farsi valere per reclamare ciò che pensano gli sia dovuto. Hanno deciso di muoversi compatti perché banalmente l’unione fa la forza.
Sì, perché uno che blocca si può ignorare, trentasei che si coordinano sono più difficili da aggirare.
E se gli standard della SPUR Coalition diventano la norma del settore, l’accesso ai contenuti potrebbe diventare qualcosa da negoziare, non una risorsa da depredare e saccheggiare impunemente.
Per i grandi editori, questa strategia ha senso e ha già prodotto risultati concreti, come gli accordi di Reuters con Microsoft e Meta dimostrano. Per i siti più piccoli, il calcolo è più delicato: bloccare ha costi in termini di visibilità futura, non bloccare ha costi in termini di valore ceduto gratuitamente.
Il dilemma è amletico, non nascondiamoci!
La selettività prudente, a mio parere, scegliendo caso per caso quale bot merita accesso e quale no, sarebbe la strada per evitare entrambi gli estremi.
Il momento di fare questa riflessione è adesso, non quando il cambiamento sarà già completato.
Hai un file robots.txt. Un consulente SEO esperto sa come agire.
Chiediti a questo punto: la porta sul retro del mio bar è ancora spalancata?
Per capire come proteggere il tuo traffico, adattare la SEO all’era delle AI e prendere decisioni strategiche sul tuo sito, contatta la nostra agenzia SEO per una consulenza personalizzata.
Insieme capiremo quale strategia è migliore per proteggere i tuoi contenuti senza rinunciare alla visibilità sui motori di risposta.
Bloccare o no i crawler AI? Domande frequenti
Perché Reuters e Time stanno bloccando i crawler AI?
Reuters e Time stanno bloccando i crawler AI per limitare lo scraping gratuito dei contenuti e spingere le aziende di intelligenza artificiale verso accordi di licenza. L’obiettivo non è fermare ogni bot, ma rendere l’accesso ai contenuti una trattativa economica basata su uno scambio di valore equo.
Il file robots.txt basta per fermare i bot AI?
Il file robots.txt da solo non basta, perché funziona solo se i crawler decidono di rispettarlo. Secondo il testo, una parte rilevante degli scraping effettuati dai bot AI ignora le indicazioni esplicite del robots.txt, rendendo necessarie strategie più selettive e strumenti di controllo più avanzati.
Conviene bloccare tutti i crawler AI?
Bloccare tutti i crawler AI può essere rischioso, soprattutto per siti piccoli e medi che dipendono dalla visibilità online. La strategia più equilibrata è distinguere tra bot di addestramento, che usano i contenuti senza generare traffico, e bot di ricerca, che possono ancora offrire citazioni e visite verso il sito.

Hanno capito il gioco: il contenuto non è traffico, è un dataset. Lo vendono via API, mica lo regalano ai bot. Chi si lamenta del click-through perso non ha ancora capito che il modello di business è già cambiato da un pezzo.
I media vendono l’accesso, i piccoli si lamentano. Solita storia. L’AI è un treno: o ci sali vendendo il biglietto o ti stende. Se non hai un asset di valore da vendere alle macchine, sei solo rumore di fondo.
I colossi alzano i loro ponti levatoi dorati, negoziando pedaggi per l’accesso all’informazione. Chi resta fuori dal castello è destinato a diventare il cibo gratuito per le macchine, una disparità che merita una riflessione.
@Sara Benedetti La chiamano disparità, io la chiamo martedì. I grandi vendono l’accesso, noi siamo il buffet gratuito. Più che una riflessione, mi chiedo a che ora chiude la mensa delle macchine.
@Sara Benedetti La metafora del castello è romantica, ma la realtà è una semplice catena alimentare: i grandi vendono l’accesso al loro territorio, gli altri diventano foraggio a basso costo. Quale parte di questo prevedibile meccanismo economico necessitava esattamente di una riflessione?
Mentre i re dell’editoria vendono le chiavi del regno, i piccoli creatori diventano fantasmi digitali. La vera abilità non è creare, ma farsi pagare.
@Carlo Caruso, il piano sarebbe regalare i contenuti e poi sperare in un accordo? Sembra un modello di business solidissimo. Soprattutto per noi piccoli.
Mentre i titani dell’editoria negoziano il prezzo della nostra cultura digitale, i loro accordi blindati non sono che il banchetto funebre per ogni creatore indipendente, destinato a diventare mangime gratuito per l’algoritmo. Quando inizieremo a pagare per pensare?
I colossi editoriali monetizzano i loro archivi tramite accordi esclusivi, mentre gli autori indipendenti teorizzano sulla visibilità offerta da macchine che li ignorano. Un paradosso che rende la mia professione di formatore tanto remunerativa quanto, apparentemente, inutile.
I grandi gruppi editoriali si barricano dietro accordi di licenza. E tutti gli altri? I piccoli e medi creatori restano scoperti, materiale gratuito per addestrare modelli altrui. Dov’è finita la democratizzazione promessa da queste tecnologie?
Il buffet gratis è finito. Le AI devono passare alla cassa, come tutti gli altri.