Tutto ciò che devi conoscere sul file robots.txt – e non solo – per approvare o negare ai motori di ricerca l’accesso a file e cartelle sul tuo sito
Nelle scorse settimane abbiamo visto parecchi elementi cruciali per l‘ottimizzazione SEO del tuo sito web – elementi cari e alla base del lavoro di ogni buon consulente SEO. Ti ho parlato del tag title, del tag meta description, dei tag heading H1…
Tutta roba importantissima ma, diciamolo, davvero molto semplice da maneggiare a livello operativo per chi utilizza dei CMS come WordPress.
Grazie a queste piattaforme user friendly, infatti, ci si può dedicare quasi interamente al SEO copywriting senza mai – o quasi – sporcarsi le mani con il linguaggio HTML o con altri processi complessi e insidiosi: è tutto lì, già bello che pronto!
Occhio, però, che non è sempre tutto così facile e immediato. Nossignore: per poter ottimizzare alla perfezione un sito web è necessario anche andare oltre a quello che ci mette a disposizione di volta in volta WordPress, e persino più in là di quello che ci fa notare puntualmente il plugin Yoast.
Tu, che hai imparato ad ottimizzare nel migliore dei modi i titoli, le parole chiave e le meta descrizioni del tuo portale, sai come ottimizzare il file robots.txt?
E soprattutto, sai perché dovresti investire un po’ del tuo tempo per farlo?
Ti dico subito una cosa. Nonostante non tutti conoscano il valore del robots.txt, questo è certamente uno dei passaggi chiave per l’ottimizzazione e l’indicizzazione SEO di un sito web.
Attenzione: un problema di configurazione del file robots potrebbe danneggiare enormemente il tuo portale, con un forte impatto negativo sul posizionamento e sul traffico.
Ok, non spaventarti. So che basta il nome robots.txt per farti preoccupare, ma ti garantisco che se leggerai con attenzione questo post ogni mistero sarà svelato e potrai godere di un sito web realmente più amico e ottimizzato (nel dettaglio) per i motori di ricerca.
Che cos’è il file robots.txt?
Come sicuramente sai – o meglio, come certamente hai già letto in qualche guida SEO – i motori di ricerca come Google scansionano in lungo e in largo i contenuti della rete attraverso i crawler di Google.
Parliamo quindi di bot, perché sono proprio loro i destinatari del nostro file robots.txt.
Questo file testuale è uno strumento che dice ai crawler – e quindi a Google, a Yahoo!, a Bing e a Yandex – quali URL tuo sito web possono scansionare e quali invece devono saltare durante il loro instancabile lavoro di indicizzazione.
Direi che fino a qui è tutto chiaro, no?
Detto con parole molto semplici, potremmo guardare al file robots.txt come ad un semaforo che indica le porte chiuse – però, come vedremo, non chiuse a chiave – accompagnate, in certi casi, da alcune porte aperte. Vuoi mettere a tacere qualche directory o pagina? Il robots.txt ti aiuta a suggerire a Big G come apparire su Google.
Se hai letto i miei precedenti articoli sull’ottimizzazione SEO hai già capito che i motori di ricerca, quando indicizzano il mare magnum dei siti che sono online, non guardano a caso di qua e di là. Nossignore: posano invece lo sguardo su determinati elementi particolarmente descrittivi e rappresentativi come il tag title, gli headings tag come il tag h1 e via dicendo.
Ma prima di tutto questo, prima di fare qualsiasi altro passaggio, Google crawler si mette a leggere velocissimamente il contenuto del tuo file robots.txt.
Già da questo dovresti capire che questo file testuale è davvero essenziale per l’indicizzazione del tuo sito web, perché è proprio a partire da questa lettura che i motori di ricerca creano la lista di URL da indicizzare.
Ok, vedo che la nebbia intorno al robots.txt inizia pian piano a diradarsi. Vedrai che, tra qualche paragrafo, ci sarà un bel cielo sereno. Andiamo avanti?
Ma… è proprio obbligatorio avere il file robots.txt?
Sì, immagino che tu te lo stia domando: ma il file robots.txt è proprio necessario?
È naturale farsi questa domanda, perché siamo fondamentalmente pigri e, se non afferriamo concretamente lo scopo di un’azione, se non capiamo che è proprio obbligatoria, allora non troviamo la voglia di compierla. Per questo motivo voglio subito toglierti ogni dubbio e renderti immediatamente operativo dicendoti che sì, il robots.txt è davvero obbligatorio, non puoi farne a meno. Se vuoi aumentare le visite al sito sbarrare la porta al crawler di Google rappresenterebbe infatti un grosso, grossissimo errore.
Il motivo è semplice: un crawler che arriva su un sito e non trova questo file assume automaticamente che in quel portale è tutto pubblico, e che quindi tutte le pagine vanno scansionate e indicizzate, con le brutte conseguenze che ti spiegherò più avanti.
Bene, ora hai capito che non puoi proprio fare a meno di questo file. Ipotizziamo allora che tu adesso ti senta obbligato a realizzarne uno, quindi inizi a farlo controvoglia e senza metterci troppa attenzione.
Cosa può succedere se il tuo file robots.txt non è formattato alla perfezione?
Beh, ovviamente ogni singolo errore può portare a problemi diversi, ma in generale ti posso dire che nei casi in cui un crawler non riesce a capire il contenuto di un file robots.txt, non farà altro che agire di testa sua, mettendosi a scansionare a destra e a manca tutte le pagine del tuo portale, un po’ come se non esistesse nessun file robots.txt.
Tra tutti c’è però un errore che devi assolutamente evitare di fare, ovvero quello di creare un file robots.txt che blocchi totalmente l’accesso ai motori di ricerca. In questo caso la diretta conseguenza sarebbe infatti pesantissima: i crawler non sfiorerebbero nessuna delle tue pagine e le rimuoverebbero una dopo l’altra dal proprio indice, rendendoti nel tempo pressoché introvabile attraverso i motori di ricerca. E questo non lo vuoi di certo, non è vero?
Bene, sai cosa vuol dire tutto questo? Che il file robots.txt va assolutamente realizzato, ma solo e unicamente dopo aver capito alla perfezione come procedere.
Dunque abbiamo visto cos’è questo particolare file e qual è la sua funzione. Ma tu – sì, proprio tu – con quale obiettivo dovresti decidere di metterci mano?
Stai leggendo quest’articolo perché vuoi ottimizzare il file robots.txt del tuo blog? Non perderti le mie dritte SEO per i blogger. Leggi l’approfondimento: Come scrivere un blog
[thrive_lead_lock id=’2743′][dkpdf-button][/thrive_lead_lock]
Per quali motivi dovresti utilizzare il file robots.txt?
Ciò che ogni esperto SEO potrebbe dirti è che ci sono due utilizzi comuni del file robots che ti possono aiutare ad ottimizzare al meglio il tuo portale, ovvero:
A) Il primo motivo per utilizzare questo file è quello di bloccare i motori di ricerca rispetto a determinate directory o pagine del tuo sito web. Immaginiamo che tu voglia chiudere cortesemente la porta in faccia al crawler davanti alla tua pagina “chi siamo”. Ebbene, nel file robots.txt si leggerà una cosa del tipo:
User-agent:* Disallow: /Chisiamo
Semplice e immediato, no?
B) Immaginiamo che il tuo sito sia davvero grande. Parlo di tante, tantissime pagine, e quindi di un sito in cui il processo di scansione e di indicizzazione può essere davvero pesante. Il primo istinto dei crawler sarà quello di scansionare tutte le cartelle, tutte le sottocartelle e tutte le pagine, ma per l’appunto questa operazione può essere piuttosto gravosa e influenzare così negativamente le performance del portale.
CONCETTO IMPORTANTE: IL CRAWL BUDGET
Questo accade perché i crawler di Google e degli altri motori di ricerca non vanno avanti ad aria, ma al contrario utilizzano corrente, server e risorse reali. Ecco perché ad ogni sito, specialmente in fase iniziale, viene assegnato un basso “crawl budget“, ovvero un numero abbastanza limitato di pagine scansionabili.
Se il crawler passa il suo tempo dietro a file e cartelle inutili consumerà (ahimè) il numero di pagine scansionabili sul tuo sito, tralasciando quelle importanti che vorresti venissero indicizzate e posizionate.
Ed è proprio qui che entra in gioco il file robots.txt, il quale restringendo l’accesso in determinate aree del sito alleggerisce il processo di scansione.
Bada bene: non si deve mai tagliare fuori il crawler dalle pagine in modo casuale, ma bisogna escludere solo quelle pagine che non sono importanti ai fini della SEO e quindi del posizionamento. Così facendo ridurrai il carico a livello del tuo server e allo stesso tempo farai viaggiare più velocemente il processo di indicizzazione.
Occhio: il robots.txt potrebbe anche essere snobbato dai crawler
Sarebbe naturale pensare che, una volta che detto ai crawler di non andare a ficcare il naso in una determinata pagina attraverso un “disallow” nel nostro file robots.txt, questi se ne stiano bene alla larga. Peccato che non succeda sempre così. E questo perché quelle contenute in questo file testuale sono delle direttive, degli accalorati consigli, delle richieste, ma non delle regole ferree.
Forse ora stai pensando di lasciar stare la SEO e diventare social media manager. Fidati, aspetta ancora qualche minuto.
Insomma, i motori di ricerca potrebbero semplicemente decidere di non seguire le tue direttive. Nella maggior parte dei casi lo faranno, ma talvolta possono decidere altrimenti e infischiarsene dei tuoi “disallow”.
Per questo motivo, se hai dei contenuti che davvero non vuoi indicizzare… beh, per essere certi di non farli finire nell’indice ti consiglio di proteggere quella particolare directory con una password. Oppure potresti più semplicemente usare il file htaccess o, ancora, inserire l’opzione “noindex” nella sezione “head” della tua pagina.
Che dici? Vuoi vedere come si fa? Eccoti servito.
Come proteggere una directory con il file .htaccess.
Per fare questa operazione devi sapere che ti servono due file.
Il primo è il file “.htaccess” che trovi nella root del tuo server, quantomeno nella stragrande maggioranza dei casi.
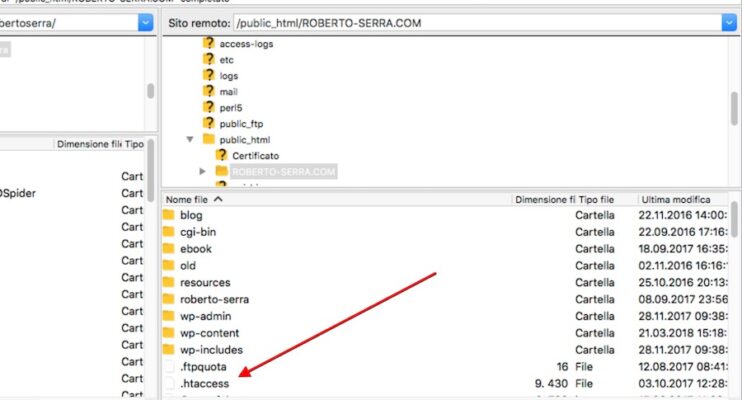
Il secondo file che ci serve è il file “.htpasswd”. A differenza del primo, questo file dovrai crearlo tu a manina con un comune editor di testo .txt.
I sistemi spesso non consentono la generazione di file che iniziano con il punto. Per questo motivo:
- nomina il tuo file htpasswd.txt
- spostalo sul server sopra la root public_html
- rimuovi l’estensione .txt e rinominalo “.htpasswd”
Una volta creato e nominato il file, al suo interno dovrai inserire le password che intendi usare per bloccare le cartelle.
In giro per la rete trovi tantissimi tool nati per questo scopo. Io ti segnalo htaccesstools.com.
Vai su htaccesstools.com e genera una password criptata fornendogli user e password in chiaro.
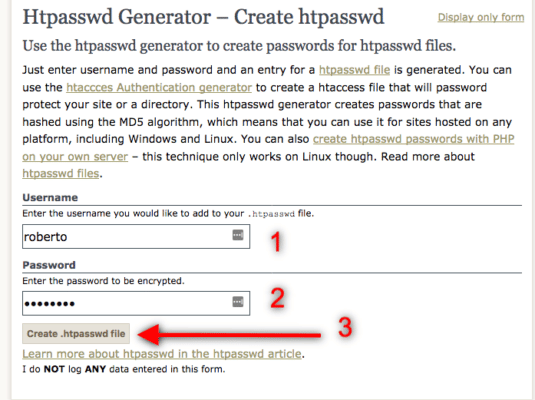
Ottimo, a questo punto hai la tua password criptata pronta per essere copiata e incollata dentro il file correttamente posizionato sopra la root public_html. Ora che il file htpasswd contiene la tua lista di nomi utente e password abilitati, andiamo sul file htaccess e diciamoli che dovrà seguire queste istruzioni.
Digitiamo dunque quanto segue:
AuthUserFile /home/root-sito/.htpasswdAuthGroupFile /dev/nullAuthName "directory"AuthType Basic<Limit GET POST>require valid-user</Limit>
Ora ti basterà spostare/copiare questo file nelle cartelle che vuoi proteggere e il gioco è fatto. Nessun crawler potrà accedere.
Perché i motori di ricerca non seguono rigidamente le istruzioni contenute nel file robots.txt?
I motivi sono tantissimi. Per fare un esempio, molto spesso alcune delle pagine che tu ha indicato come “chiuse” nel tuo file robots.txt vengono comunque presentate nei risultati di ricerca a causa di uno o più link diretti verso quelle stesse pagine da altre fonti già indicizzate.
Se una delle tue pagine indicizzate contiene un link ad una risorsa dichiarata in disallow nel robots.txt, i motori di ricerca tenderanno comunque ad indicizzarla. L’unica eccezione si ha quando in quest’ultima e contenuta la dichiarazione “meta noindex” nella zona <head>.
Insomma, con il file robots.txt non ci sono mai vere e proprie garanzie – ma i SEO più esperti sanno fin troppo bene che, quando si ha a che fare con i motori di ricerca, quasi nulla è del tutto certo.
Come funziona il robots.txt?
Avrai già iniziato a intuirlo: la struttura interna del robots.txt è davvero semplice e una volta compreso il suo funzionamento è difficile sbagliare. Devi solo capire cosa sono le varie etichette che si incontrano in questo file, ovvero (tra le principali):
- User-agent
- Disallow
- Allow
- Crawl-delay
- Sitemap
Andiamo allora a vedere il loro significato e le loro funzioni, vuoi?
User-agent: questo valore indica il crawler al quale vengono indirizzate le direttive seguenti . Per riferirsi al crawler generale di Google si indicherà dunque Googlebot, per le sole immagini Googlebot-Image, per Baidu Baiduspider, per Bing Bingbot e via dicendo. Se invece vuoi riferirti a tutti i crawler, ti basterà inserire un asterisco (*).
Disallow: è la direttiva che istruisce lo User-agent specificato a NON scansionare una determinata URL. Insomma è il vero cuore del file, la sua profonda ragion d’essere.
Allow: al contrario di Disallow, questa direttiva esplicita quali pagine o quali sottocartelle possono essere scansionate. Ma perché serve questa direttiva, quando sappiamo che i crawler sono portati a scansionare automaticamente ogni URL fino a richiesta contraria? Ebbene, questa direttiva viene utilizzata soprattutto per dare accesso a delle pagine che vogliamo indicizzare e che sono però inserite in una directory tacciata dalla direttiva Disallow. Chiaro, no?
Ricordati però che Allow funziona solo e unicamente per il bot di Google.
Ecco un esempio:
User-agent: GooglebotDisallow: /libriAllow: /libri/ilmiolibro/
Crawl-delay: questa speciale direttiva serve per dire ai crawler di aspettare un determinato quantitativo di tempo prima di scansionare la prossima pagina del sito web. Il valore da inserire si intende in millisecondi.
In questo caso devi sapere che Googlebot fa orecchie da mercante davanti a tale direttiva. Insomma, puoi usarla per Bing, Yahoo! e Yandex, ma non per Mister G, per il quale invece devi andare a cambiare il setting all’interno della Google Search Console.
Sitemap: questa direttiva viene utilizzata per specificare al motore di ricerca la URL dove si trova la sitemap del sito.
Come si realizza un file robots.txt?
Bene, ora sai più o meno tutto quello che dovresti conoscere su questo importante file. Ma come si crea un file robots.txt a regola d’arte?
Beh, come dice il suo stesso nome, si tratta di un file testuale. Non ti servono dunque strumenti particolari, ti basterà avere libero accesso al Notepad di Windows e al pannello di controllo del tuo sito web, e…
Ma aspetta, non è che tu il file robots.txt ce l’hai già?
Beh, scoprirlo non è affatto difficile. Anzi, ti dirò di più: praticamente chiunque potrebbe farlo. Ti basterà aprire il tuo browser, digitare il nome del tuo domino e aggiungere la stringa “robots.txt”, ovvero:
https://www.pincopallino.com/robots.txt
Ti esce una pagina bianca con queste parole (o qualcosa di estremamente simile)?
User-agent: * Allow: /
Allora vuol dire che il tuo file robots.txt in realtà esiste già e che tutto quello che devi fare è modificarlo a dovere.
Come si modifica un file robots.txt?
La prima cosa da fare è scaricare il tuo file robots.txt (utilizzando ad esempio un server FTP) e aprirlo con Notepad o con un altro editor di testo. Una volta effettuate le modifiche necessarie, ti basterà ricaricare la nuova versione sul tuo server.
E, invece, come si crea dal nulla un file robots.txt? Se non hai trovato alcun file robots.txt nel tuo dominio, allora devi assolutamente crearne uno: crea un file di testo, inserisci le direttive in base alle tue esigenze e caricalo immediatamente sotto alla root directory del tuo sito web.
Occhio, i crawler riconosceranno il tuo file (e dunque lo useranno) solo e unicamente se questo si chiama esattamente robots.txt. Nomi come “ilmiorobots.txt” non vanno bene e nemmeno “Robots.txt” con iniziale maiuscola, in quanto il nome del file è case-sensitive. Quindi, mi raccomando, scrivi tutto in minuscolo!
Vuoi un esempio base di un file robots.txt? Eccolo qua:
User-agent: * Allow: / Sitemap: https://esempio.com/sitemap.xml
Come avrai certamente già capito, il file robots.txt qui sopra (privo di ogni specifica) dà libero accesso a tutto il tuo sito web. Il che, però, non è una buona idea, tant’è che perfino Google nelle sue linee guida ci ricorda di “non consentire la scansione dell’intero sito web“. Tutti quelli che bazzicano nel mondo SEO sanno bene che, in quei rari casi in cui Google si sbilancia in questo modo, è davvero il caso si ascoltarlo!
Ricordi il crawl budget di cui ti ho parlato sopra? Ecco, facciamo in modo di non sprecarlo.
Come essere certi di avere realizzato un file robots.txt efficace?
Bene, ora potresti aver terminato il tuo robots.txt inserendo tutti i vari disallow e allow. Come puoi essere certo di aver fatto un bel lavoro?
Ebbene, per tua fortuna non devi affidarti al caso né pregare la divinità della SEO – che davvero non so quale possa essere. Google nella sua Search Console ha messo a nostra disposizione uno strumento estremamente utile, ovvero il Tester dei file robots.txt.
Ti basterà fare login nel tuo account Google Search Console, inserire il tuo file e testarlo.
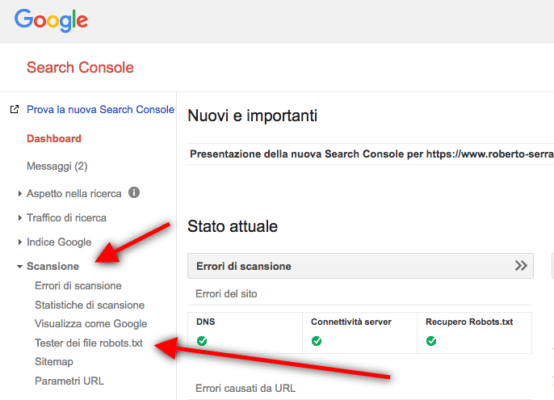
Se non ci saranno errori Google ti darà il foglio di via, altrimenti evidenzierà la stringa o le stringhe di testo errate così da permetterti di individuare l’errore e risolverlo prima di metterlo online.
Il file robots.txt e WordPress
Sì, lo so, appena hai letto questo titoletto ti è venuto un infarto. Tranquillo, tutto quello che hai letto fino ad ora vale anche per te che usi WordPress, né più né meno. Ci sono solamente alcuni particolari dei quali devi tener conto, ovvero:
- Prima del 2012 i siti WordPress dovevano bloccare con il file robots.txt l’accesso alle cartelle wp-admin and wp-includes. Dal 2012 in poi, però, non è più necessario farlo, in quanto è lo stesso WordPress che provvede allo scopo inserendo uno speciale tag “noindex” nelle pagine interessate.
- Devi inoltre sapere che il file robots di default di WordPress è sempre cosi:
User-agent: *Disallow: /wp-admin/Allow: /wp-admin/admin-ajax.php
Nel caso tu – per assurdo – voglia scoraggiare i crawler a indicizzare il tuo intero sito, ti basterà attivare l’apposita opzione nelle impostazioni del tuo CMS e il risultato sarà questo:
User-agent: *Disallow: /
- WordPress usa dei file robots.txt virtuali. Questo significa che non puoi modificarli direttamente: puoi solo crearne uno nuovo e sostituirlo alla tua directory principale.
Cosa non fare sul file robots.txt?
Per essere certo di trasformare il file robots.txt in un alleato per l’ottimizzazione SEO del tuo sito, il tuo primo passo deve essere quello di testarlo attraverso l’apposito tester di Google così da controllare che il robots non finisca per oscurare della pagine che tu vuoi invece far apparire nei risultati del motore di ricerca.
Altro consiglio fondamentale è di non bloccare mai le cartelle CSS o JS: i crawler hanno infatti la necessità di vedere il tuo sito web come lo vedrebbe un utente reale in carne e ossa; se dunque le tue pagine abbisognano di CSS e di JavaScript per funzionare questi non possono essere nascosti ai bot. Chiaro?
Non osare – se non è strettamente necessario – dare direttive diverse ai differenti bot dei motori di ricerca: potresti finire per creare della confusione. A questo va aggiunto che sarebbe molto difficile tenere aggiornato il file robots.txt con queste specifiche differenziate. Il mio consiglio per avere un file robots.txt davvero ottimizzato è quello di usare lo user-agent:*, così da avere delle direttive uniche per tutti i diversi crawler.
Se il tuo scopo è solo e unicamente quello di bloccare della pagine specifiche dall’essere indicizzate, ti consiglio di non passare attraverso il file robots.txt, ma piuttosto di utilizzare il “noindex” nella sezione header delle singole pagine o in alternativa modificare il file htaccess.
Conclusione
Visto? La creazione e l’ottimizzazione del tuo file robots.txt non sono assolutamente complicate come potevano sembrare! Potrai crearlo e modificare questo file in poco tempo, e potrai essere certo di pubblicarne uno efficiente dopo averlo testato sull’apposito tool di Google.
Ora che sai tutto quello che dovevi sapere, ti consiglio di programmare quanto prima la modifica del tuo robots.txt e dare così nuovo slancio all’ottimizzazione del tuo portale!
