Se le informazioni online sono obsolete, imprecise o fuorvianti, l’intelligenza artificiale può amplificarle, influenzando negativamente l’immagine di aziende e professionisti
📌 TAKE AWAYS
L'intelligenza artificiale non si limita a rispondere alle domande: aggiunge spesso confronti, consigli e informazioni prese dal web, che possono essere obsolete o errate.
Per questo è fondamentale controllare come il proprio brand viene raccontato e pubblicare contenuti chiari, aggiornati e facilmente leggibili anche dalle AI.
Quando qualcuno chiede a un motore di risposta AI un consiglio sul tuo settore, il tuo brand salta fuori?
E se sì, cosa dice esattamente di te?
Cosa racconta, con quali parole, con quale voce?
Hai passato anni a costruire il modo in cui il tuo brand viene percepito, a scegliere ogni frase del sito, a far tesoro di ogni recensione. E adesso c’è un narratore invisibile che si è messo a raccontare la tua storia al posto tuo, senza chiederti il permesso e, soprattutto, senza mandarti la bozza prima di pubblicarla.
La buona notizia è che oggi essere citati da un’intelligenza artificiale può valere quanto comparire in prima pagina su Google, forse anche di più. La cattiva notizia, quella che pochi ti raccontano, è che venire nominati dall’IA non basta.
Puoi anche essere la risposta che l’IA sceglie di dare, e nonostante questo ritrovarti descritto con un prezzo vecchio di sei mesi, una funzione che hai eliminato, un confronto con un concorrente che nemmeno esiste più.
Un po’ come scoprire che il tuo miglior venditore, quello che parla con più clienti di chiunque altro in azienda, sta ripetendo a memoria un listino prezzi del 2023. Sorride, è convincente, ma sta dicendo cose sbagliate a tua insaputa, milioni di volte al giorno.
Perché l’intelligenza artificiale non si limita a rispondere. Ti racconta cose che non hai chiesto. Aggiunge un parere, un confronto, un consiglio non richiesto, un po’ come quel parente al pranzo di Natale che ti dà suggerimenti su tutto: dovresti cambiare lavoro, forse non dovresti trasferirti in quella città, la dieta che stai seguendo non mi pare efficace…
Tanti “preziosi” consigli… peccato che nessuno glieli abbia chiesti!
Solo che qui il parente parla a milioni di persone contemporaneamente, e quello che dice sul tuo brand può essere vecchio, impreciso o semplicemente sbagliato.
Il fenomeno ha già un nome, ed è azzeccato quanto imbarazzante: si chiama “Parrot Problem“, il problema del pappagallo.
L’IA ti dà molto di più di quello che chiedi (e può essere un grosso rischio)
Intendiamoci, il team di ricerca di Profound non si è inventato nulla.
Conosciamo il termine “pappagallo stocastico” già da anni. Ha avuto successo perché descrive bene il modo in cui funzionano i modelli linguistici come ChatGPT.
“Pappagallo” perché ripetono e rielaborano ciò che hanno imparato dai testi con cui sono stati addestrati, senza comprendere davvero il significato delle parole. “Stocastico”, invece, significa probabilistico: l’IA sceglie ogni parola calcolando quale sia la più probabile da usare dopo quelle precedenti.
Questo le permette di produrre testi fluidi e convincenti, ma non garantisce che siano corretti. Se i dati di partenza sono incompleti o la probabilità porta fuori strada, il modello può generare informazioni false o inventate, le cosiddette “allucinazioni“.
Ma cosa sarebbe questo “Parrot Problem” teorizzato da Profound?
Partiamo da un assunto, prima. L’intelligenza artificiale tende a ripetere e rielaborare le informazioni che trova sul web, aggiungendo spesso confronti, consigli e opinioni anche quando nessuno glieli ha chiesti.
Quale potrebbe essere il problema, dunque?
Semplice. Che se quelle informazioni sono vecchie o sbagliate, l’IA finisce per ripeterle e diffonderle.
Per studiare questo comportamento, il team guidato dall’analista Jasman Singh ha analizzato cinquantamila richieste rivolte a diversi motori di intelligenza artificiale, distribuite su sette settori e cinque tipi di domande.
Il risultato è sconcertante: quasi la metà delle risposte, il 47 per cento per la precisione, conteneva contenuti editoriali che l’utente non aveva mai richiesto!
Confronti tra prodotti concorrenti, opinioni, consigli, tabelle comparative spuntate dal nulla.
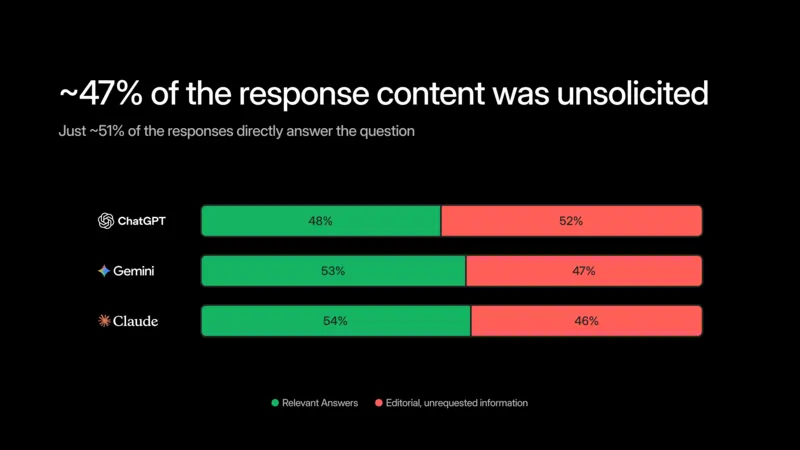
Il punto è che questi sistemi non sono affatto sintetici come si potrebbe pensare. ChatGPT genera in media 3.043 caratteri per risposta, Gemini si ferma a 2.921, Claude è il più asciutto con 1.590. Per farti capire l’ordine di grandezza, ChatGPT può riempire in una singola risposta lo spazio di dieci post su X.
E in tutto quello spazio, qualcosa deve pur finirci dentro. Se la domanda non basta a riempire la pagina, l’algoritmo va a cercare altrove, prende un po’ di contesto, un po’ di opinione, e te lo serve tutto insieme come se fosse farina dello stesso sacco.
I ricercatori di Profound hanno individuato sette tipologie di questo contenuto extra, dalla motivazione dietro una scelta alle tabelle di confronto, dai suggerimenti sui passi successivi fino ai veri e propri consigli di acquisto.
Tutto materiale che l’IA pesca da fonti terze, spesso senza verificarne la veridicità.
Prendi il caso di Southwest Airlines, citato proprio nello studio di Profound. Se chiedi quale compagnia aerea sia la migliore per viaggi di gruppo, alcuni motori rispondono correttamente ma poi aggiungono un piccolo consiglio in più, elogiando la storica politica dei posti non assegnati della compagnia.
Peccato che Southwest abbia abbandonato quella politica a gennaio del 2026!
L’informazione che sembra un valore aggiunto diventa in realtà un boomerang, perché racconta al pubblico qualcosa che non è più vero.
Il pappagallo legge la tua pagina, ma non sempre capisce cosa c’è scritto
C’è un altro pezzo di questa storia, forse ancora più interessante perché ci porta dietro le quinte del meccanismo. Il consulente Suganthan Mohanadasan ha fatto una cosa davvero interessante: ha aperto gli strumenti di sviluppo del proprio browser e ha letto per giorni interi il traffico di rete generato da ChatGPT mentre rispondeva alle sue domande. Non i testi finali, ma il codice grezzo che passa dietro le quinte prima che la risposta arrivi sullo schermo.
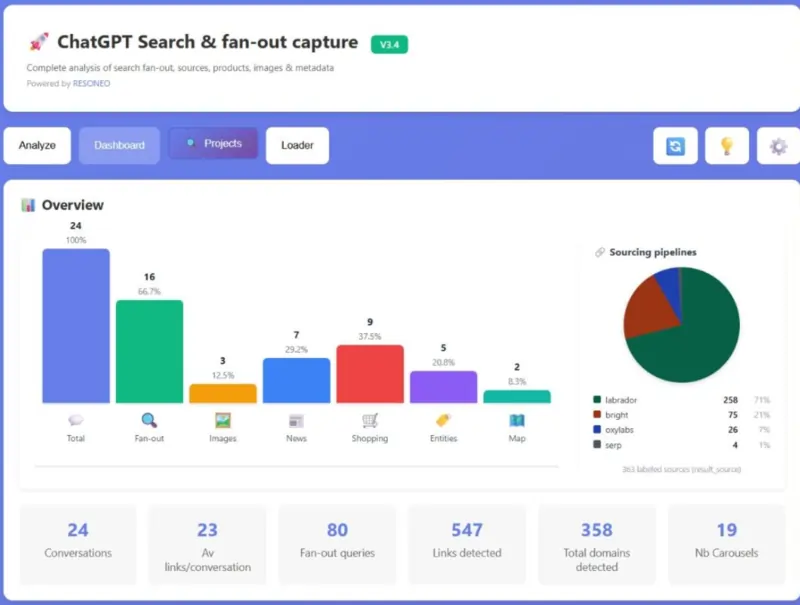
Quello che ha trovato è un campo chiamato result source, un’etichetta invisibile all’utente che indica da dove arriva ogni singola fonte usata dal modello.
Ci sono quattro valori possibili.
Uno è il web aperto, quello che chiunque può indicizzare.
Un altro, chiamato labrador, sembra riservato a un gruppo ristretto di editori autorevoli come Reuters, il Guardian, il Wall Street Journal, Wikipedia, testate che con ogni probabilità hanno accordi diretti con OpenAI.
Gli altri due sono i nomi di due aziende di web scraping, Bright Data e Oxylabs, che si occupano di raccogliere e restituire contenuti dal resto del web, quello che tu e io possiamo effettivamente scrivere e pubblicare.
La conseguenza pratica è semplice quanto scomoda da digerire.
Se non lavori per una grande testata con un contratto diretto con OpenAI, il tuo terreno di gioco è quello scremato dagli scraper commerciali. E per essere raccolto da loro, il tuo contenuto deve essere leggibile in modo pulito, con testo semplice in HTML, senza numeri nascosti dentro immagini o caricati tramite JavaScript.
Mohanadasan ha documentato casi in cui ChatGPT provava letteralmente a leggere una pagina di prezzi di un concorrente di Profound, non riusciva a trovare i numeri perché erano generati dinamicamente, e finiva per abbandonare quella fonte e citare invece un sito di recensioni terzo. Il tuo prezzo, raccontato da qualcun altro, semplicemente perché la tua pagina non si lasciava leggere.
E qui arriva un altro dettaglio che vale la pena raccontarti, perché smonta una convinzione molto diffusa. Non tutto quello che l’IA legge finisce citato.
Nell’analisi di Suganthan, Reddit veniva letto 278 volte ma citato solo 11 volte, mentre YouTube veniva letto 201 volte e non citato nemmeno una.
La ragione è affascinante: quando il modello legge una pagina YouTube, ottiene solo i metadati del video, non la trascrizione vera e propria, mentre un thread di Reddit è già tutto testo leggibile.
Il messaggio che ne esce è chiaro: puoi essere ovunque, ma se il contenuto non è testo leggibile e strutturato, l’IA ti guarda e va oltre.
I dati che ti appartengono valgono più di qualsiasi opinione
Se fin qui il quadro ti è sembrato un po’ fosco, c’è anche una buona notizia. I dati originali restano l’arma più difficile da copiare per un concorrente.
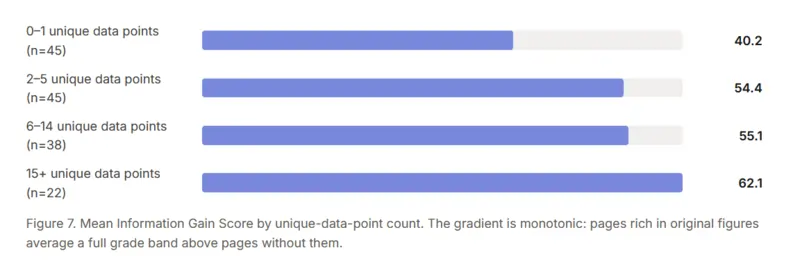
Uno studio della piattaforma On Page AI, che ha analizzato centocinquanta pagine tra le prime tre posizioni di Google su cinquanta parole chiave in dieci settori diversi, ha misurato quanto ogni pagina aggiungesse di informazione realmente nuova rispetto al resto dei risultati.
Le pagine con al massimo un dato originale ottenevano un punteggio medio di 40,2 punti, quelle con quindici o più dati originali arrivavano a 62,1.
Più numeri tuoi metti in campo, più diventi difficile da ignorare, sia per un motore di ricerca classico che per un chatbot.
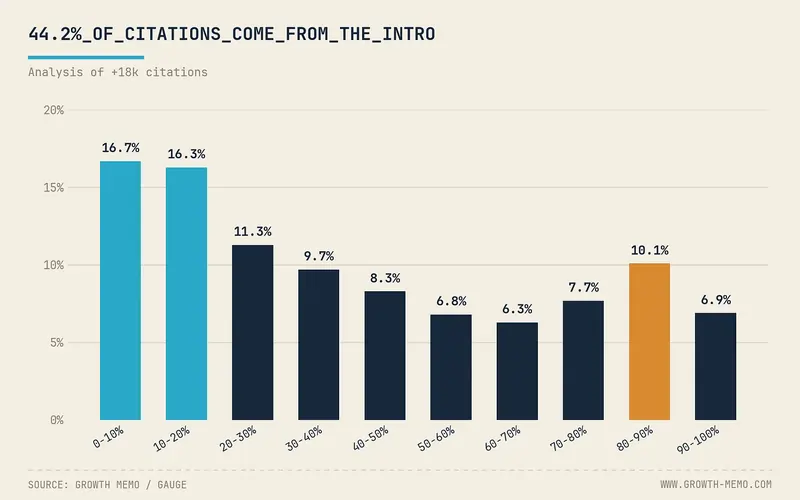
Attenzione però, perché possedere il dato non basta a garantirti la citazione. Il team di Growth Memo ha analizzato 18.000 citazioni verificate di ChatGPT e ha trovato una distribuzione che hanno soprannominato “a rampa da sci”: il 44,2 per cento delle citazioni arriva dal primo 30 per cento della pagina, un altro 31,1 per cento dalla parte centrale, mentre tutto quello che finisce nella parte finale ha una probabilità di essere citato di due volte e mezzo inferiore.
Se nascondi il tuo dato più forte dopo venti paragrafi di introduzione, quel dato per l’IA semplicemente non esiste.
Immagina di scrivere la lettera più importante della tua vita e infilare la frase chiave nel post scriptum. Ecco, è più o meno quello che fanno molte aziende con i propri contenuti.
Bada bene, però: chi possiede il dato originale ma lo scrive in modo confuso rischia comunque di perdere la citazione a favore di chi lo riprende e lo presenta meglio.
Pensa a quei siti aggregatori che confezionano il tuo numero in una tabella più chiara della tua. Fa rabbia, lo capisco, ma è la regola del gioco attuale.
Per questo conviene mettere il dato più forte nelle primissime righe, spiegare subito cosa misura e su quale campione, dichiarare con chiarezza la metodologia, ed evitare quella narrazione lenta che crea un po’ di suspense (anche meno, non sei Hitchcock!) che tanto piace ai lettori umani ma che l’intelligenza artificiale, occupata a scandagliare centinaia di pagine al minuto, semplicemente salta.
I click calano ma il tuo valore resta
C’è infine un tema che riguarda direttamente il tuo portafoglio.
Con l’arrivo delle risposte generate direttamente nei motori di ricerca, molte aziende hanno visto crollare il traffico diretto verso i propri contenuti pur mantenendo, in alcuni casi, un fatturato quasi stabile.
Di fronte a numeri così, la domanda è sempre la stessa: perché continuare a investire se il ritorno si sta riducendo?
I report classici guardano solo all’ultimo click prima dell’acquisto.
Ma questo modo di misurare non basta più, perché sottovaluta il vero contributo del sito. I report dovrebbero guardare anche alle “conversioni assistite” (come le chiama il SEO Nick LeRoy), cioè a tutti i clienti che il blog ha aiutato a convincere lungo il percorso, anche se poi hanno comprato altrove o giorni dopo.
Ecco allora perché tenere sotto controllo solo click e conversioni dirette oggi rischia di farti chiudere un rubinetto che, in realtà, alimenta anche altri canali, rafforza la ricerca del tuo marchio e sostiene le performance della pubblicità a pagamento.
Il pappagallo dell’intelligenza artificiale continuerà a raccontare la tua storia, con o senza il tuo permesso.
Puoi lasciare che lo faccia leggendo dati vecchi trovati chissà dove, oppure puoi dargli materiale fresco, chiaro, verificabile, scritto per essere letto da una macchina prima ancora che da un umano di passaggio.
Contatta la nostra agenzia SEO GEO allora e vediamo insieme come raccontare la tua storia nel modo giusto: quello che porta clienti veri e vendite reali, prima che ci pensi qualcun altro al posto tuo.
Il “Parrot Problem” – quando l’IA ripete ciò che trova sul web (anche gli errori): domande frequenti
Che cos’è il Parrot Problem nell’intelligenza artificiale?
Il Parrot Problem indica il rischio che l’intelligenza artificiale ripeta e rielabori informazioni trovate online senza distinguere sempre tra dati corretti, vecchi o sbagliati. Se sul web circolano informazioni obsolete su un brand, l’IA può amplificarle nelle sue risposte.
Perché essere citati dall’IA non basta?
Essere citati dall’IA non basta perché conta anche il modo in cui un brand viene descritto. Un’azienda può comparire in una risposta, ma essere raccontata con prezzi superati, funzioni eliminate o confronti non più validi.
Come si può ridurre il rischio di essere descritti male dall’IA?
Per ridurre il rischio bisogna pubblicare contenuti aggiornati, chiari e facili da leggere anche dalle macchine. Dati, prezzi e informazioni importanti dovrebbero essere in HTML semplice, ben strutturati e non nascosti in immagini o elementi caricati tramite JavaScript.

Mentre voi parlate di sabbia, io sto già indicizzando i miei dati proprietari. L’IA non è un pappagallo, è lo specchio delle vostre mancanze.
Il cosiddetto “Parrot Problem” è solo il problema di chi non ha mai curato il proprio sito. L’IA non fa che evidenziare la pigrizia passata. Per molti sarà un risveglio piuttosto brusco.
Federica Testa, abbiamo costruito cattedrali digitali su fondamenta di sabbia, e l’IA ora fa solo tremare il terreno. La questione non è la tecnologia, ma la nostra negligenza. Quanti avranno la lucidità di ricostruire dalle basi?