Il posizionamento non riguarda solo la SEO e i motori di ricerca, è ora di entrare nei LLM col tuo brand: con il Data Poisoning ci puoi riuscire (se sai come fare)
Immagina di essere un paninaro. Si, proprio uno di quelli che fa panini unti e bisunti.
Ora immagina un utente che interroga un LLM chiedendogli “chi è nella top 3 dei paninari più buoni in Italia” e che ChatGPT ci metta dentro il tuo nome (magari aggiungendo: “si dice che dopo averli provati anche il ragù di tua madre potrebbe non essere più una priorità”).
Ecco vedi, il mio esempio fa un po’ ridere (almeno spero 😅), ma ti posso garantire che in futuro non riderai neanche un po’ se hai un’azienda di qualsiasi tipo e in quella top 3 – o giù di lì – il tuo nome non ci finirà dentro.
Perché ora che i Large Language Model stanno entrando dappertutto, devi considerare che anche la visibilità nel digital del tuo business si sta rivoluzionando come mai prima (soprattutto a livello organico, ma non solo).
Se vuoi sapere cosa succede e cosa c’entra il Data Poisoning ti consiglio di leggere quanto segue e capirai perché questa tecnica mi ha rapito anche più delle polpette domenicali di mia nonna.

Se i LLM sono il futuro tu devi sapere come funzionano (e prepararti)
Togliamo di mezzo quel “SE”. I large language models (LLM) SONO il futuro e in parte sono già anche il presente.
Li chiamiamo a caso “intelligenza artificiale”, ma gli LLM per l’esattezza sono modelli avanzati di machine learning progettati per comprendere e generare testo in linguaggio naturale.
Detta così, me ne rendo conto, sembra quasi una fesseria, un giochetto, ma questa forma l’intelligenza artificiale generativa sta già avendo impatti che vanno ben al di là della tua e della mia immaginazione.
È una roba che si sta insinuando a piccoli passi nel DNA del nostro sistema sociale ed economico e posso garantirti una cosa: è qui per restare.
Magli LLM, devi sapere, non sono poi l’ultimissima novità. Guardiamo qualche esempio:
| 🤖Modello | 🔎Funzionamento |
|---|---|
| GPT-3 | (Generative Pre-trained Transformer 3) – Sviluppato da OpenAI, è uno dei modelli di linguaggio più avanzati e noti, capace di generare testi coerenti e contestuali in vari ambiti e per diversi scopi. |
| Google Bert | (Bidirectional Encoder Representations from Transformers) – Creato da Google, BERT è progettato per comprendere il contesto di una parola in una frase utilizzando sia la direzione sinistra che quella destra dei contesti circostanti. |
| Gemini AI | Il modello Gemini è noto per le sue capacità avanzate di elaborazione del linguaggio naturale, che lo rendono adatto a una vasta gamma di applicazioni, tra cui chatbot, assistenti virtuali, generazione di testo, traduzione automatica e molto altro. |
I primi modelli avanzati di IA generativa, come GPT-1 e BERT, sono stati lanciati nel 2018, ma non sono stati resi subito disponibili al pubblico, piuttosto lavoravano dietro le quinte. Ad esempio, nel caso di BERT, la tecnologia era usata per comprendere meglio i testi generati da esseri umani e caricati sui siti web.
Il pubblico, invece, ha ricevuto e pure gratis, un prodotto finito e avanzato basato su IA generativa solo il 30 novembre 2022, quando OpenAI ha stravolto il mondo con il lancio di ChatGPT.
Da quel momento è cambiato tutto. Si è innescata una corsa all’oro tecnologico dell’IA che ha portato OpenAI a trasformarsi da realtà no-profit a multinazionale pluri-miliardaria in 12 miseri mesi (con Google a cercare di rispondere colpo su colpo, se pur con qualche affanno).
Fin qui ci siamo, ma cosa è successo dopo e soprattutto, come hanno fatto queste azienda a creare modelli così avanzati e così potenti da poter generare linguaggio a un livello prima consentito solo agli esseri umani?
Da dove arriva la “conoscenza” dei LLM? Una questione di addestramento
Guardiamo per un attimo a uno strumento come ChatGPT. Come si nota ha un’interfaccia dal funzionamento piuttosto intuitivo:
- Un campo da riempire con la propria domanda o “comando”, comunemente detto prompt;
- Un pulsante per l’invio dell’input alla macchina.
In pochi secondi il modello genererà un testo di ottima qualità e semanticamente orientato sul prompt inserito dall’utente. Si può andare dalla veloce risposta a un quesito, alla generazione di un intero contenuto, di una tabella o addirittura di codice informatico in vari linguaggi e molto altro.
Ma la domanda che viene spontaneo farsi nell’osservare le righe di testo che “poppano” sullo schermo a una velocità impossibile da seguire è:
In base a cosa tira fuori le informazioni l’LLM di turno per generare risposte?
Giochiamo un attimo a Chi vuol essere milionario:
A – Conosce davvero le cose, come un essere umano;
B – Cerca le robe su Google e fa finta di dare le risposte lui;
C – Bill Gates ha nascosto 100k cyborg umanoidi in un magazzino enorme a sfornare risposte h24 con Sam Altman a coordinare le operazioni;
D – Chiede l’aiuto da casa.
Sebbene all’inizio mi sembrava palese che la risposta corretta fosse la C, purtroppo ho dovuto ricredermi quando ho scoperto che i modelli LLM operano su calcoli probabilistici basati su pattern riconoscibili nel linguaggio umano.
Per dirla con le parole di Sam Altman, uno dei co-fondatori di OpenAI:
I modelli linguistici sono strumenti ideati per prevedere la parola successiva in una sequenza basata su parole viste in precedenza
Sam Altman
Fin qui ci siamo, ma allora esattamente da dove prende le informazioni un modello come ChatGPT?
In una parola: da dataset, ovvero raccolte organizzate di dati di ogni tipo (numerici, testuali, immagini, video etc.) utilizzati per l’analisi e l’addestramento di modelli di machine learning.
E i dati da dare in pasto all’IA per addestrarla li prendono da…?!
BOH! Per quanto ne sappiamo potrebbero prenderli ovunque.
Su questo non abbiamo assolutamente le idee chiare. Soprattutto perché non c’è una totale trasparenza della provenienza dei dati che le aziende come OpenAI utilizzano per lo sviluppo dei modelli (scatenando anche diverse proteste e controversie legali).
Ma è proprio qui che il discorso si fa interessante, soprattutto se hai un’azienda. Perché se desideri essere protagonista con il tuo brand in certi tipi di risposte generate da IA su piattaforme come ChatGPT o Google (anch’esso basato sempre più su un LLM come Gemini AI) devi essere presente e rilevante nei dataset dai quali pescano le informazioni.
Come stai per scoprire, con tecniche come il data poisoning diventa possibile influenzare l’addestramento della macchina, con potenziali benefici per la visibilità di un brand che di certo non penseresti mai di ignorare se di mestiere fai l’imprenditore 😉.
Manipolare l’addestramento dell’IA con il Data Poisoning per influenzarne gli output
Dunque, ora sai che l’IA viene addestrata a generare risposte pescando informazioni e studiando pattern da dataset di enormi proporzioni.
E se ti dicessi che in parte è possibile intervenire sulla fase di addestramento per manipolare i dati che l’IA ha a disposizione per il machine learning con l’obiettivo di influenzare i risultati del modello stesso?
So che suona complicato, e credimi lo è, ma è proprio questo il principio alla base del data poisoning. Un pratica che mira a manipolare i dati di addestramento di un modello di machine learning, influenzando così le sue prestazioni e in qualche caso la sua affidabilità.
Se ti fai una ricerchina online, infatti, scoprirai che non è esattamente una pratica lusinghiera. In altre parole: è associata al mondo degli attacchi informatici.
Facciamo un paio di esempi?
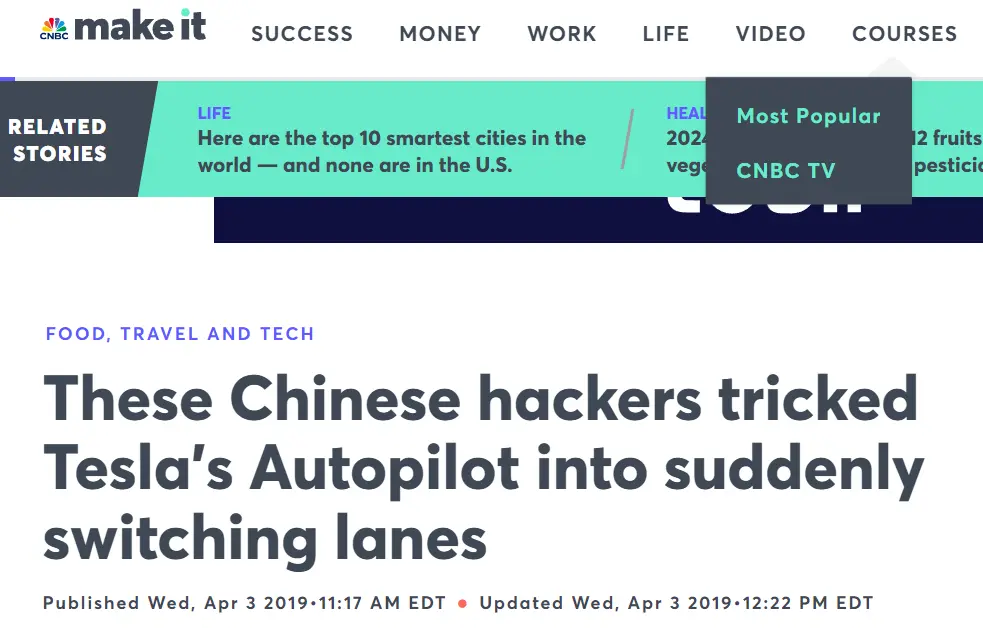
Posso parlarti di quella volta in cui degli hacker cinesi alterarono il dataset su cui si basa la guida autonoma delle vetture Tesla convincendole che la cosa migliore da fare fosse andare contromano.
Oppure del simpatico caso in cui la potentissima e infallibile intelligenza artificiale di Google fu indotta a credere che l’immagine di una tartaruga giocattolo rappresentasse in effetti un fucile…
Qui la povera tartaruga incriminata:

Ora però aspetta un attimo perché voglio rassicurarti su un paio di cose:
- No, non sono un hacker (anche se smanetto tantissimo col pc e con i dati);
- No, non ti sto consigliando di fare niente di illegale.
Il punto, ripeto, è che ho capito (sperimentando e studiando parecchio la cosa negli ultimi anni) che è realmente possibile influenzare i modelli LLM con il data poisoning per fargli dire quello che vogliamo
SPOILER: la cosa è del tutto legale e non fa male a nessuno, al contrario, può far bene al tuo business.
Data Poisoning e SEO: il futuro della visibilità e del posizionamento nei LLM secondo la mia esperienza
Se analizzi il contesto del digital marketing e della visibilità online per come si è evoluto negli ultimi anni ti accorgi facilmente di alcuni processi fondamentali in atto:
- La tecnologia sta cambiando tutto alla velocità della luce;
- Adattarsi per sopravvivere nel mercato restando rilevanti è sempre più complesso;
- La visibilità sta diventando merce rara e bisogna essere sempre più preparati, strutturati (e facoltosi) per ottenerla.
Data una situazione simile, già da qualche anno, mi è parso chiaro che per prevedere come si evolvono le chance di visibilità di un brand, sia vitale studiare le tecnologie che ne influenzano i canali di contatto col pubblico.
Da qui è nato il mio interesse per gli LLM a partire proprio dai modelli di Google, come Bert, ben prima che questi strumenti fossero inseriti in piattaforme al servizio del grande pubblico.
Ora l’IA è finalmente entrata – e di prepotenza – nella vite delle persone, sia attraverso i motori di ricerca come Google sia attraverso chatbot come ChatGPT. È normale dunque doversi fermare a capire oggi quale sia l’evoluzione della SEO e del posizionamento del proprio brand in termini di visibilità nei nuovi strumenti.
Io penso di aver trovato almeno una parte della risposta a questo problema. E soprattutto ritengo che le tecniche che ne scaturiscono, possano risultare valide sia per gli LLM sia per gli ultimi sviluppi dei motori di ricerca come quello di Google.
Essere TU la risposta dell’IA quando un utente cerca un prodotto o servizio della tua nicchia: è possibile?
In sostanza, quello che ho fatto in passato, come consulente SEO, è stato un lavoro di manipolazione del motore di ricerca per sbilanciare la sua “opinione” in favore delle aziende dei miei clienti (ovviamente attraverso processi di costruzione di qualità e autorevolezza per i loro siti web, non certo roba da hacker che durasse meno di un fuoco artificiale a capodanno).
E dunque, quello che propongo oggi è la possibilità di fare lo stesso con il data poisoning negli LLM. Questa tecnica è in qualche modo la nuova SEO perché permetterà di “posizionarsi” all’interno del sistema di addestramento dell’IA per garantirsi un posto d’onore quando si parla di un certo prodotto, servizio o settore.
Ricordi l’esempio del paninaro di cui prima? Restiamo in quella nicchia e proviamo a fare a ChatGPT una semplice domanda:

Per cercare di rispondere ChatGPT ha fatto una ricerca web, elaborando il tutto a partire da un sito web straniero ritenuto per qualche ragione affidabile nello stabilire quali siano i migliori produttori di schiacciate in Italia.
Ma, se ci pensi, questo dimostra essenzialmente un paio di concetti, a mio avviso importantissimi:
- Che i LLM recuperano costantemente informazioni dal web per provare a dare risposte affidabili agli utenti.
- Che dunque l’addestramento dell’IA non ha mai fine perché apprende continuamente da internet e dalla interazione con gli utenti (pazzesco).
Appare evidente dunque, che la conseguenza di tutto ciò sia la possibile efficacia di tecniche di “data poisoning injection” per manipolare l’addestramento della macchina.
Come? Fornendo al suo dataset tutta una serie di contenuti, informazioni e punti di riferimento molto autorevoli per fargli dire quello che vogliamo e prenderci così la tanto agognata visibilità.
“Rob, ma come diavolo pensi di realizzare una cosa del genere?”
Senza iniziare a parlarti in ostrogoto di inutili dettagli tecnici, ti posso dire che la parte più massiccia del processo prevede la creazione di contenuti (articoli, video, immagini, post sui social etc…) che affermano ripetutamente e da molteplici fonti, che la tua azienda è la migliore nel fare X e Y, che il tuo brand da anni si occupa di Z, che i tuoi prodotti hanno una certa affidabilità nel fare una cosa etc, etc…
Aggiungo che per realizzare il processo sarà importante l’utilizzo di proxy per simulare che i dati di addestramento provengano da fonti sempre diverse. Ogni proxy rappresenta un “computer” unico, creando l’illusione di un vasto numero di utenti che interagiscono con il modello plasmandone le opinioni.
Questo aiuta a evitare il rilevamento di attività sospette e rende il processo di data poisoning più credibile.
Insomma, se nMILA persone da posti diversi scrivono tante volte nel tempo che TU e sempre TU sei il migliore a fare u pani ca’ meusa (panino con la milza tipico palermitano) è altamente probabile che il modello sia indotto a credere che sia così e dirlo a chiunque gli chieda un parere in merito.
A quel punto è probabile che ad avere la fila davanti al chioschetto per avere un panino, sarai proprio tu.
Mi spiego?
L’off-site sempre più centrale e il concetto di Semantic Building
Come dicevo prima, molto di tutto questo dipende dai contenuti che circolano sul web e che parlano di te, della tua azienda, del tuo brand e dei tuoi prodotti e servizi. In tal senso conta molto sia la quantità che la qualità dei contenuti in circolazione.
Per concludere dunque, mi preme sottolineare che oggi quando si parla di SEO, gran parte dell’evoluzione del settore deriva dal peso crescente dell’attività off-site. A cambiare maggiormente, infatti, è uno degli storici fattori di posizionamento organico su Google: la link building (il processo di costruzione di un profilo di backlink autorevole che punta verso il proprio sito web come segnale di autorevolezza).
Ciò comporta il grande aumento dell’importanza di costruire una presenza multi-canale con contenuti autorevoli, arrivando ormai probabilmente a parlare non più di link building, ma di “semantic building”. Concetto che meglio si presta a rappresentare l’esigenza di impattare tutto l’ecosistema di un dataset, piuttosto che soltanto i cari vecchi collegamenti ipertestuali verso il proprio sito web.
E con tutta la modestia del caso, ci tengo però ad aggiungere che per chi come me gestisce ormai da anni servizi di link building non sarà poi un gran salto della quaglia passare ad offrire un servizio di semantic building (intorno al quale faccio pratica e studio ormai da un pezzo).
In questo articolo ho voluto mettere la bandierina su uno dei concetti più importanti (e ignorati) in termini di rilevanza organica futura e posso capire bene che tu abbia ancora più di un dubbio. Se così fosse non temere, scriverò di più e meglio da qui a breve, non appena otterrò i risultati dell’ennesimo test che ho in corso 🙂
Se poi ti va di parlarmi del tuo progetto, sai dove andare a bussare!
#avantitutta

🏆 Take Aways…
- I Large Language Models stanno trasformando il panorama della visibilità digitale.
- Il Data Poisoning può influenzare positivamente il posizionamento del tuo brand.
- I LLM sono addestrati su dataset di enormi proporzioni per generare risposte.
- Manipolare l’addestramento dei LLM con tecniche legali di Data Poisoning è possibile e vantaggioso.

Certo, il mio nome finirà tra i migliori LLM, con o senza la tua arte.
Quel paninaro che non fa piangere nemmeno la nonna, ecco il futuro. Magari mettiamoci pure l’aglio, che non si sa mai.
Ah, il paninaro “unto e bisunto” che domina i LLM. 🤦♂️ Che genialata. 👏
Il “paninaro” nei LLM? Un’immagine forte. Ma la visibilità su queste piattaforme richiede più di un’intuizione. I risultati concreti restano la vera misura del successo. Puntare al bersaglio giusto, non solo al clamore.
Il paninaro da LLM? Ottima intuizione, se non puntate al topping giusto.
Fuffa digitale. Vendete fumo, io faccio soldi.
La visibilità nei LLM è il nuovo palcoscenico: conquistalo con intelligenza, non con rumore di fondo. La maestria, non la distorsione, porta il vero successo.